顯著性消失了?HAC 修正下的時變參數重新檢定
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
顯著性消失了?HAC 修正下的時變參數重新檢定
一、為什麼要重做一次「已經顯著」的檢定?
實證研究最常見的反派不是「資料造假」,而是 自己騙自己 。同一份數據,用看似合理但隱含瑕疵的統計方法跑一遍,往往能得到漂亮但脆弱的結論;換成更嚴格的標準再跑一遍,結論就化為烏有。本次實驗 K1140 正是這樣的反思演習:我們把先前 K1114 已經宣稱「達顯著水準」的三項時變參數結果,全部以 HAC(Newey–West)穩健標準誤、區塊置換 Spearman、以及區塊自助法重做一遍,看看在合理的自相關修正下還剩下什麼。
故事要從 K1114 說起。該實驗用滾動視窗(window=500 個交易日,step=21 個交易日)估計多重 GARCH 方程式中盈餘公告變異效應(earnings-announcement variance, EAV)的時變係數 θ_EAV,得到台積電(TSMC)、聯電(UMC)、聯發科(MediaTek)三檔半導體股票各自一條 θ_EAV 時間序列(128/132/124 個觀察點)。對這三條序列分別做了三類檢定(線性趨勢、與 VIX 之相關、VIX 高低區制差異),九個假設檢定中有三項通過 BH–FDR 多重檢定校正:UMC 的趨勢、MediaTek 的趨勢、TSMC 的區制差異。
問題出在 樣本獨立性假設 。滾動視窗每次往前推進 21 天,但視窗本身寬達 500 天,意味著相鄰兩個 θ 估計值共用 479/500 ≈ 96% 的觀察值。這種高度重疊讓 θ 序列具有強烈正自相關(事後測得各檔的 lag-1 ACF 分別為 0.308、0.366、0.469),普通最小平方法(OLS)的標準誤公式假設誤差項彼此獨立、在這種設定下會嚴重低估真實標準誤,也就是說,OLS 報出來的統計強度被自相關「灌水」了。粗估有效獨立樣本數約為觀察數除以視窗對 step 比例(500/21 ≈ 24),等效樣本只有 5–6 個,而非 124–132 個。
K1114 的 README 自我質疑段已經誠實地把這個 caveat 寫了出來。K1140 就是把那個 caveat 從註腳變成正式檢定,看看 K1114 的三個「達顯著水準」是否禁得起自相關修正。
二、資料來源
- 實驗紀錄 :experiments/k1140/(README、結果 JSON、三張診斷圖、執行腳本)
- θ_EAV 序列來源 :experiments/k1114/k1114_results.json 的
per_stock_results[*]['theta2_series'],TSMC 128 個、UMC 132 個、MediaTek 124 個滾動點 - 底層日資料 :台積電(2330.TW)、聯電(2303.TW)、聯發科(2454.TW)日報酬率,VIX 平方項,搭配台股盈餘公告日歷
- 滾動視窗設計 :window=500 個交易日,step=21 個交易日,估計起點 2014 年初、終點 2025 年底
- 計算工具 :自行實作 Newey–West HAC 標準誤、區塊置換(block=24, n_perm=5000)、區塊自助法(block_size=24, n_boot=5000),固定 seed=42
整個實驗 完全沿用 K1114 已產生的 θ 序列、不重新跑 GARCH 估計 ,所以 K1140 是純粹的「事後分析」(retrospective analysis),沒有策略回測、沒有未來資訊滲漏(lookahead)。需要釐清一點:K1114 在每個滾動視窗內做的回歸都只用該視窗截止時點之前的歷史資料,也就是說「θ_t 來自 t 之前 500 日」,θ 序列本身已經是「過去資訊」的函數;K1140 對這條既有序列做趨勢檢定,無論 OLS 或 HAC 都是橫切面意義上的檢定, HAC 的修正只動標準誤、不動估計值,因此完全不影響資料時序意義上的因果方向 。換句話說,自相關修正不會引進也不會排除 lookahead,這部分由 K1114 的滾動視窗設計就已經處理乾淨。
三、方法:三層遞進的嚴格度
K1140 設計了三層由寬鬆到嚴格的檢定,刻意讓「方法論的嚴格度」這條軸線本身成為實驗變數:
- Layer 1:Newey–West HAC 標準誤 。針對每檔股票的 θ 序列做線性趨勢回歸,但用 Bartlett 核截斷的 HAC 標準誤取代 OLS 標準誤。lag 長度 L 取三個值對照:L=5(經驗式 floor(4·(T/100)^(2/9)),太短,僅作對照)、L=24(保守,覆蓋一個視窗重疊週期)、L=48(極保守,覆蓋兩個重疊週期)。我們把 L=24 視為主要結果。
- Layer 2:區塊置換 Spearman 。把 θ 序列以 block=24 切塊、隨機重排 5000 次,從零分布直接讀 p 值,避開 Spearman 漸近分布在自相關下失效的問題。
- Layer 3:KS 區制檢定 + 有效樣本數通縮 。Kolmogorov–Smirnov 統計量本身是分配層次比較,相對穩健;但對應 p 值原本假設 n 個獨立觀察,我們把 n 除以 24 作為「有效樣本數」重算 KS 分配 p 值,把重疊膨脹的影響打回去。
外加最嚴格的 Layer 4:區塊自助法趨勢檢定 。HAC 假設殘差自相關呈 Bartlett 幾何衰減,若 θ 序列存在結構性曲度(不只是 AR(1) 雜訊),HAC 仍可能持續低估標準誤。區塊自助法把 θ 切成 block_size=24 的塊、整塊重抽 5000 次重做回歸,由模擬零分布直接讀 p 值,是高重疊場景下的黃金標準。
九個 p 值(HAC L=24 趨勢×3 + 區塊置換 Spearman×3 + KS 有效樣本×3)統一以 Benjamini–Hochberg 校正多重檢定,並依 HLZ (2016) 嚴格統計建議以 BH-adj 達顯著水準(顯著性低於 0.05) 作為通過門檻。
四、結果:HAC 一加上去,光環就掉了一半
下表是核心數字(slope 為單位 step 之斜率),讀者可以直接感受 OLS 與 HAC 之間的落差:
| 股票 | OLS 統計強度 | HAC L=5 | HAC L=24 | HAC L=48 | 區塊自助法 |
|---|---|---|---|---|---|
| TSMC | 1.75(不顯著) | 0.84 | 0.76 | 0.88 | 0.80 |
| UMC | 3.06(顯著性 p≈0.003) | 2.17 | 2.45 | 3.32 | 1.91 |
| MediaTek | 4.51(顯著性 p≈1.5e-5) | 3.85 | 4.33 | 5.39 | 1.75 |
幾個直覺要先建立:
- TSMC 從一開始就不穩 :OLS 統計強度只有 1.75,本來就在門檻以下;HAC 後直接掉到 0.76–0.88,趨勢假設徹底死亡。
- UMC 從強到弱 :OLS 統計強度 3.06、達顯著水準(p≈0.003),看似強勁;HAC L=24 降到 2.45,達顯著水準(p≈0.014)但 BH 校正後達到 0.065、卡在 0.05 門檻外;區塊自助法再降到 1.91,徹底失守。
- MediaTek 的最戲劇性 :OLS 統計強度高達 4.51、達顯著水準(顯著性 p≈1.5e-5),HAC L=24 還在 4.33(顯著性 p≈1.5e-5),看似最頑強的訊號;但 區塊自助法一加,統計強度從 4.33 崩到 1.75,達顯著水準從極小躍升到 0.061 ——直接被打回不顯著。
把九個檢定一起放進 BH–FDR 校正,不同層的存活情況:
- HAC L=5: 1/9 通過 (MediaTek 趨勢,BH-adj p≈0.001)
- HAC L=24(主要結果): 1/9 通過 (MediaTek 趨勢,BH-adj p≈1.4e-4)
- HAC L=48: 2/9 通過 (UMC 趨勢、MediaTek 趨勢;但這個結論不可信,原因見下)
- 區塊自助法(最嚴格):0/9 通過
最後一行才是真正的判決。L=48 之所以反常地讓更多訊號「復活」,是因為長 lag 截斷在小樣本下標準誤估計變得極不穩定、有可能被低估而非校正,這也是為什麼方法論教科書建議在高重疊滾動回歸上不要單純依賴 HAC。區塊自助法直接從序列結構模擬零分布、不靠 Bartlett 衰減假設,得到的 p 值最值得信賴。
K1114 原本的三項顯著性結果(UMC 趨勢、MediaTek 趨勢、TSMC 區制)在嚴格修正下 全部消失 :
- TSMC 區制 KS :原本達顯著水準(p≈0.009),有效樣本通縮後 p 趨近 1.0,幾乎完全由重疊觀察膨脹而來
- UMC 趨勢 :HAC L=24 後達顯著水準(顯著性 p≈0.014)、BH 校正後 0.065、區塊自助法 0.021、BH 校正後 0.191, 系統性衰退
- MediaTek 趨勢 :HAC L=24 仍達顯著水準(顯著性 p≈1.5e-5)、區塊自助法達顯著水準(顯著性 p≈0.061), 最後一層才崩
五、三張診斷圖怎麼讀
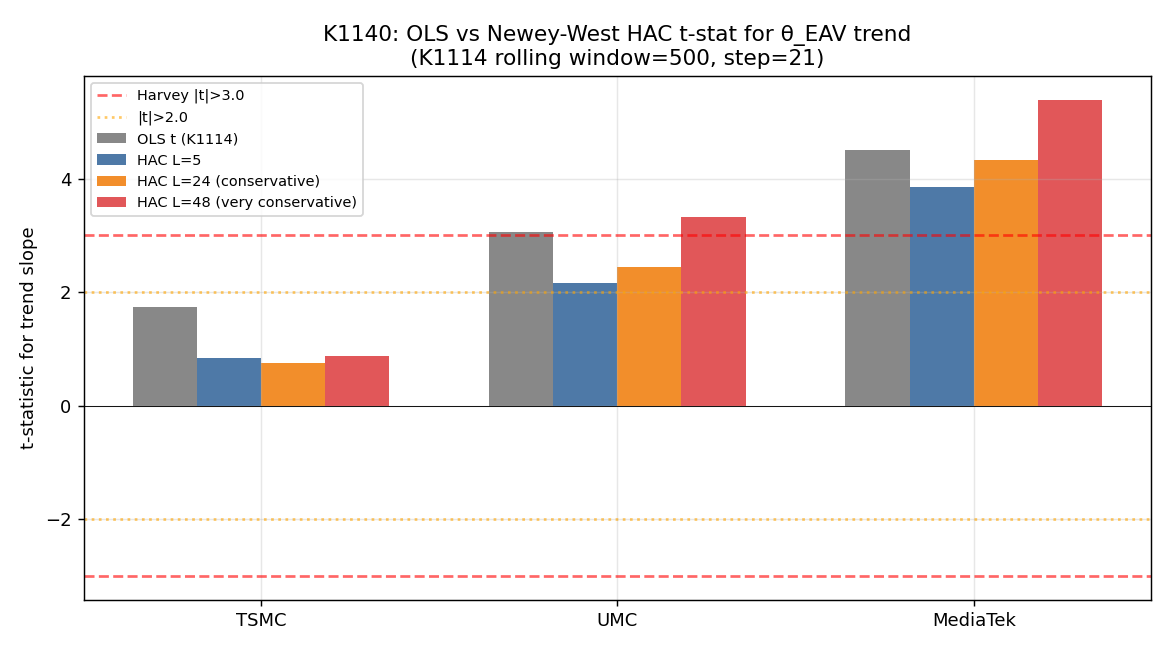
第一張圖把 OLS 與 HAC L=5/24/48 三個版本的趨勢統計強度並排呈現。TSMC 永遠在低空盤旋;UMC 從 OLS 的 3+ 降到 HAC L=24 的 2.45、再升到 L=48 的 3.32(注意這是 lag 截斷在小樣本下不穩的徵兆,不是訊號變強);MediaTek 三個 HAC 版本都看起來很穩定地維持在 4 附近,但別被騙了,這是 HAC 仍假設衰減型自相關的副作用。
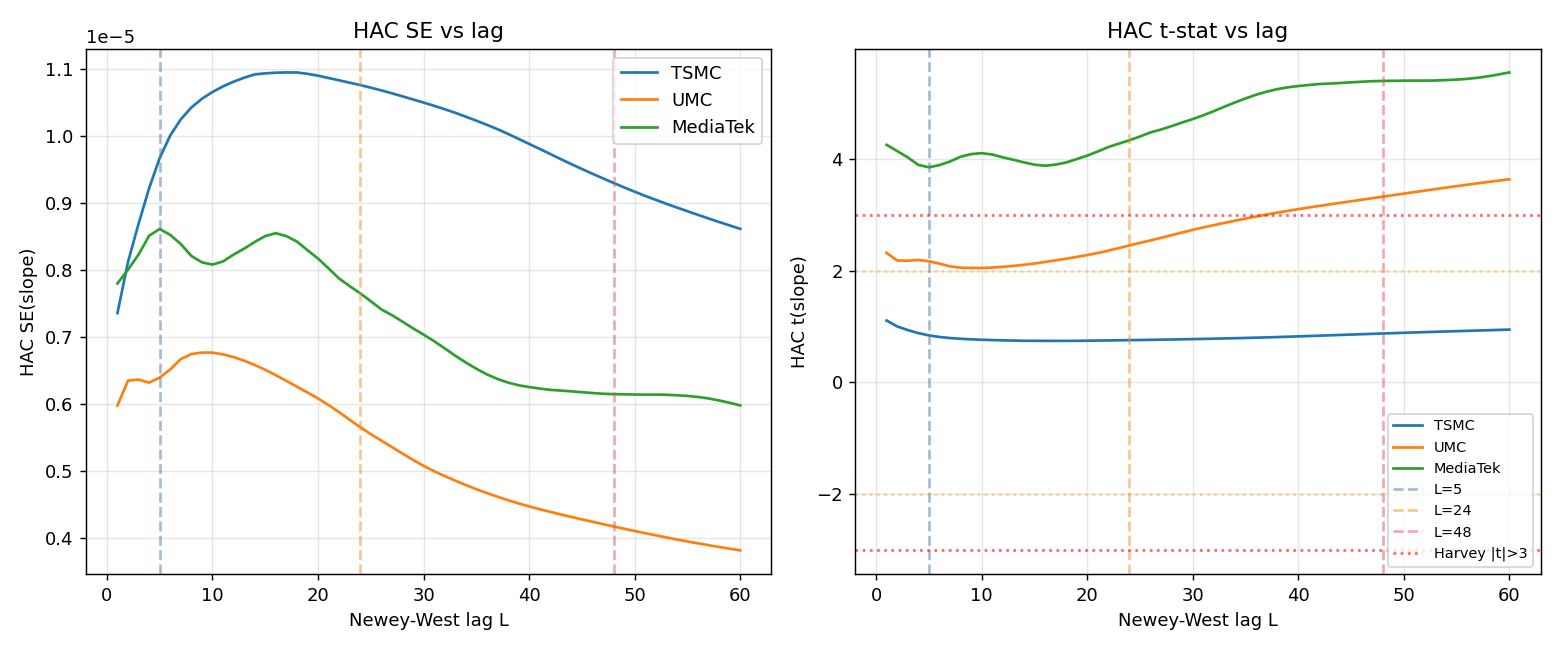
第二張圖把 lag 長度 L 從 1 拉到 60,畫出 HAC 標準誤、統計強度隨 L 變化的軌跡。理想情況下 L 在合理範圍內統計強度應該相對平坦;本次三檔股票統計強度隨 L 變化都不平坦,暗示 Bartlett 核並未完全捕捉序列結構。這正是為什麼我們追加區塊自助法,它不依賴衰減假設。
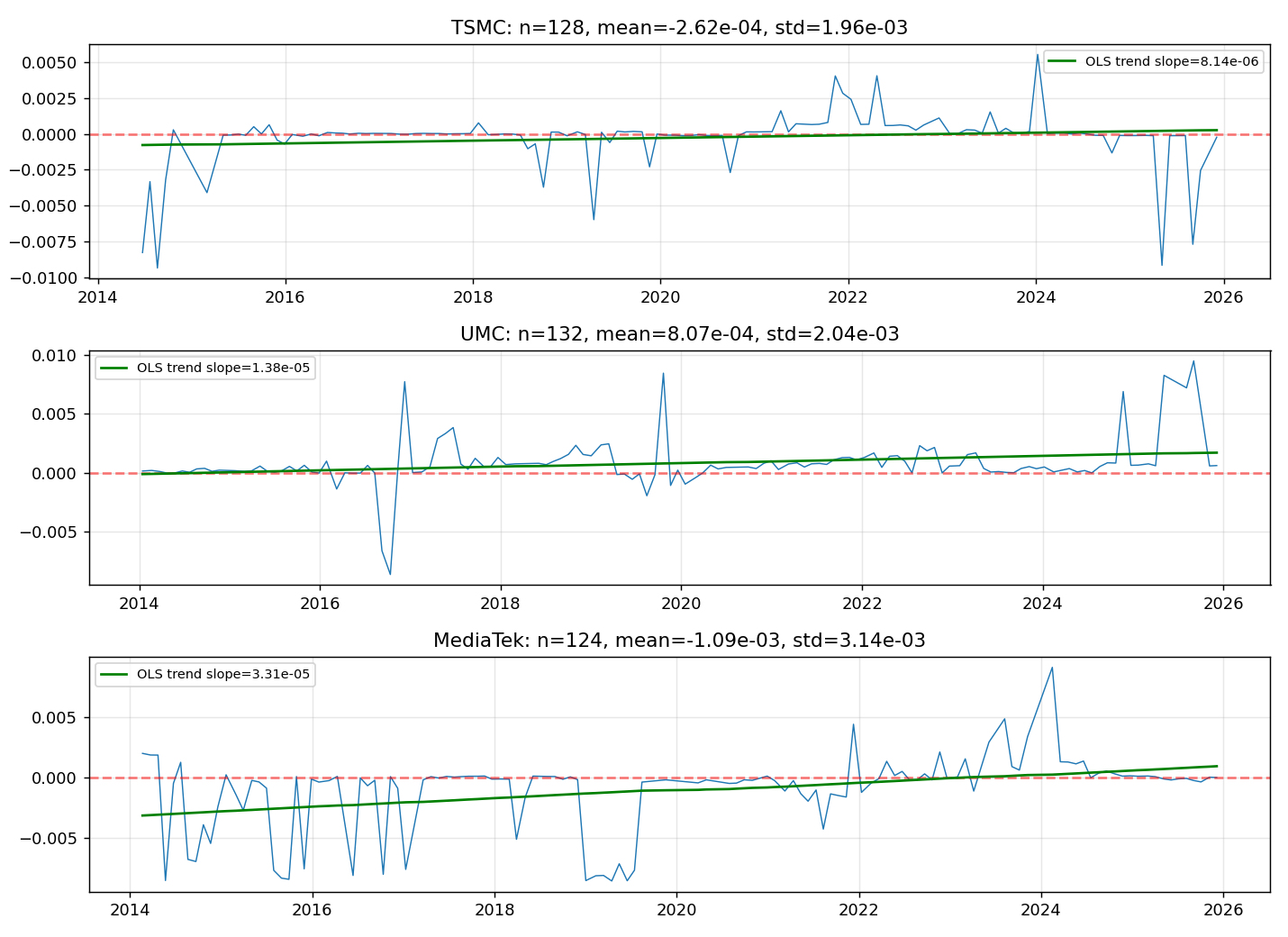
第三張圖是三檔股票的 θ_EAV 滾動序列加 OLS 趨勢線。眼睛看起來「好像有趨勢」是滾動回歸的視覺陷阱,序列被高度重疊平滑化後,連雜訊都看起來像訊號。這張圖本身就是研究誠實原則的最佳教材:不要用眼睛下結論。
六、結論:負面結果也是好結果
K1140 給出的最終裁決是冷靜的:在嚴格的自相關修正下,K1114 的三項「達顯著水準」結論全部站不住腳。三檔半導體股票的 θ_EAV 平均水準(TSMC 接近 0、UMC 為正、MediaTek 為負)作為 點估計 仍然真實,但「時間趨勢」、「VIX 區制差異」、「Spearman 相關」 都沒有 達到嚴格統計門檻。
這個結果對相關論文線(Paper 2 的盈餘公告變異效應跨產業/跨時間異質性)的意義很直接:橫斷面與時間序列雙雙無顯著差異。研究方向必須誠實面對「沒有可被嚴格檢定拒絕的異質來源」這個事實,而不是換個檢定再湊一個顯著。
更通用的教訓有三條:
- OLS 在自相關下會誇大顯著性 。滾動回歸、移動平均、共享窗口的設計幾乎都有這個問題;不做修正就直接報統計強度等於主動誤導讀者。
- HAC 是必要不充分條件 。Newey–West 是改善 OLS 的第一步,但在高重疊與曲度結構下仍可能低估標準誤;嚴肅的決策應追加區塊自助法。
- 負面結果比假性正面更有價值 。研究誠實原則的核心,就是承認「方法不夠嚴格時看到的訊號可能是雜訊」。K1114→K1140 的修正路徑,就是把這個原則具體執行給自己看。
讀者下次看到任何一篇研究宣稱「滾動回歸顯示 X 有顯著時變」的時候,請先問三個問題:相鄰估計重疊多少?標準誤有沒有 HAC 修正?有沒有更嚴格的區塊自助法當 sanity check?三題都答得出來,再考慮要不要相信那個結論。
參考文獻
- Newey, W. K., & West, K. D. (1987). A Simple, Positive Semi-definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix. Econometrica, 55(3), 703–708.
- Politis, D. N., & Romano, J. P. (1994). The Stationary Bootstrap. JASA, 89(428), 1303–1313.
- Benjamini, Y., & Hochberg, Y. (1995). Controlling the False Discovery Rate. JRSS B, 57(1), 289–300.
- HLZ (2016): 嚴格統計, C. R., Liu, Y., & Zhu, H. … and the Cross-Section of Expected Returns. RFS, 29(1), 5–68.
實驗: K1140(前身 K1114;相關 K1067、K1109、K1113) 樣本期: 2014 年初至 2025 年底 滾動設計: window=500、step=21;θ_EAV 序列共 128(TSMC)/ 132(UMC)/ 124(MediaTek)個點
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊