測了 16 個模型組合,唯一看起來成功的那個,其實是資料時序用錯了
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
測了 16 個模型組合,唯一看起來成功的那個,其實是資料時序用錯了
去年,我們測了一組問題:聯準會每週公布的金融壓力指數,能不能用來預測 ETF 的波動率?
測了四個 ETF(S&P 500、黃金、美國長債、比特幣),五種模型設定,共 16 格。結果 15 格都顯示 VIX 類的波動率基準模型完勝,額外的 alt-data 不只沒幫助,有些反而讓預測變差。
只有一格例外: TLT(美國長債 ETF)配上金融壓力指數(NFCI 系列) ,t 統計量達到 +3.74——按照嚴格的學術顯著性門檻,這算是「統計上有效」。
後來我們發現,那個數字是錯的。不是計算錯,是資料的時間用錯了。
那份資料,你其實看不到
FRED(聖路易斯聯準銀行)每週五會計算一個叫 NFCI(National Financial Conditions Index)的金融壓力指數,觀測的是那個星期的金融市場狀況。
但它不是週五公布。它的公布時間是 下一週的週三 。
換句話說,週 W-1 的 NFCI 觀測值,你得等到週 W 的週三才能看到。
在我們最初的實驗裡,程式碼用的是標準的「shift(1)」處理,把上週的 NFCI 拿來預測這週的波動率。乍看沒問題,但在每週的 週一和週二 ,shift(1) 引用的那個 NFCI 值,在現實中根本還沒公布。你預設自己在週一就能用到那份數字,但那份數字週三才出來。
這不是小細節。當模型「知道」了一份未來才會公布的資訊,它的成績自然會好一點。這就是所謂的 前視偏差(look-ahead bias) 。
修正之後:數字怎麼變
我們用「shift(2)」取代「shift(1)」,讓 NFCI 系列確保延遲兩週才使用,絕對不用到尚未公布的資料。然後重跑全部 16 個模型組合。
整體結論沒變:VIX 基準模型仍然全面勝出。
但那個唯一的例外呢?
| 資產 | 模型 | 修正前 t 統計量 | 修正後 t 統計量 | 是否仍顯著 |
|---|---|---|---|---|
| TLT | M4 金融壓力指數 | +3.74 | +1.96 | ✗(不再通過嚴格統計顯著性門檻) |
| SPY | M4 金融壓力指數 | -3.00 | -3.61 | ✓(基準模型優勢更強) |
| GLD | M4 金融壓力指數 | -3.34 | -3.00 | ✓(基準模型優勢維持) |
| BTC | M5 全部 | -1.28 | -3.64 | 跨越門檻(基準模型才是贏家) |
TLT M4 從 +3.74 跌到 +1.96,跌破了嚴格統計顯著性門檻。那個「金融壓力指數預測美債波動率」的信號,基本上是資料時序帶來的幻象。
這讓整個結論變得更強
有人可能覺得這是壞消息,好不容易找到一個有效案例,結果沒了。
但換個角度:現在 16 格 全部 都說同一件事——VIX 類的波動率指標,在預測 SPY、GLD、TLT、BTC 的週波動率上,打敗了所有 alt-data 組合。這個結論沒有例外,沒有角落案例,更乾淨,也更可靠。
而且 BTC M5(「全部 alt-data 加進去」的規格)在修正後,t 統計量從 -1.28 跳到 -3.64,反而讓基準模型的勝出更顯著。在原始結果裡,BTC M5 看起來是個模糊地帶,修正後不是了。
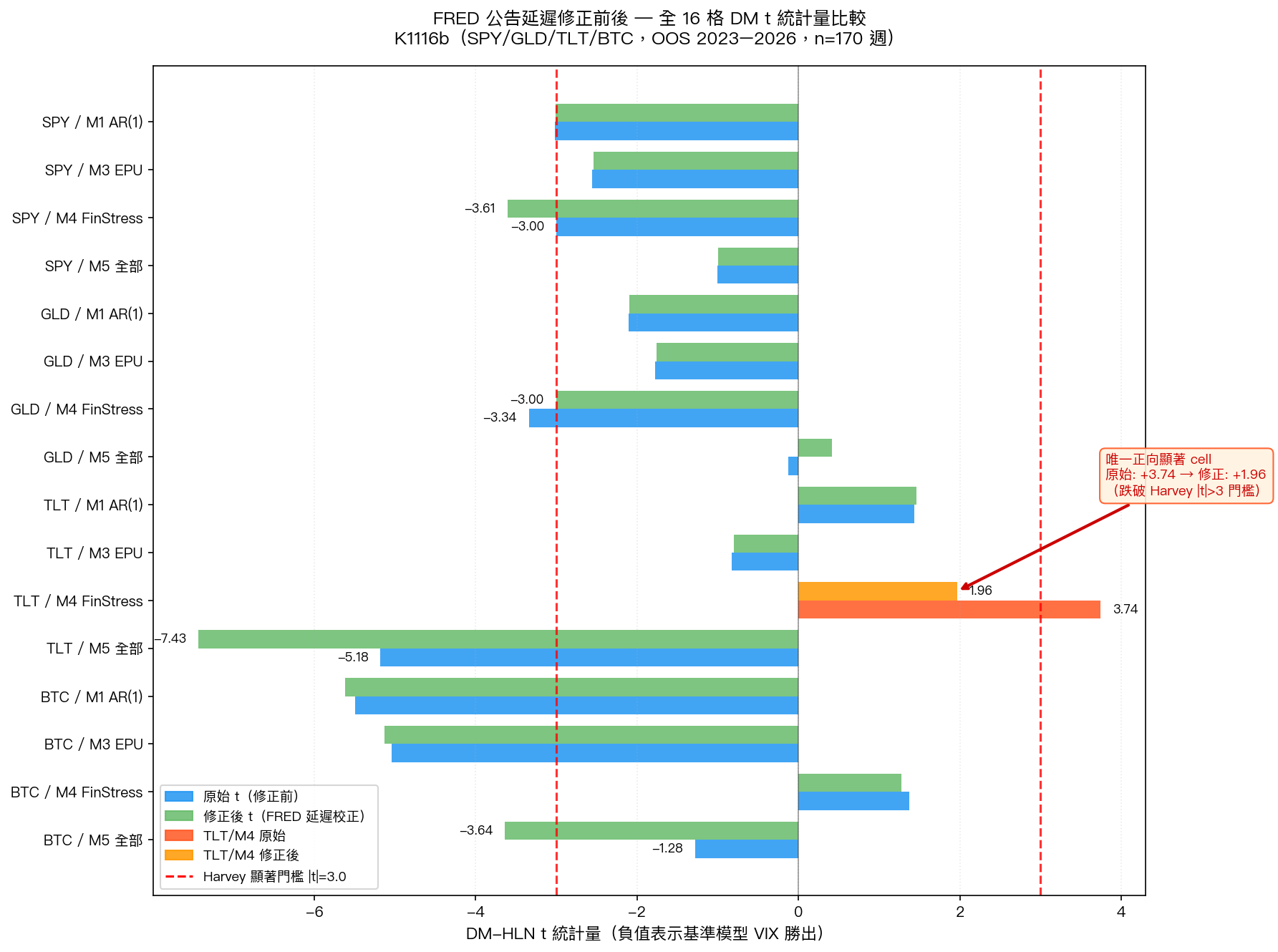 圖:修正 FRED 公告延遲前後,16 格比較檢定(DM 統計量)。負值表示基準 VIX 模型勝出;紅虛線是嚴格統計顯著性門檻。
圖:修正 FRED 公告延遲前後,16 格比較檢定(DM 統計量)。負值表示基準 VIX 模型勝出;紅虛線是嚴格統計顯著性門檻。
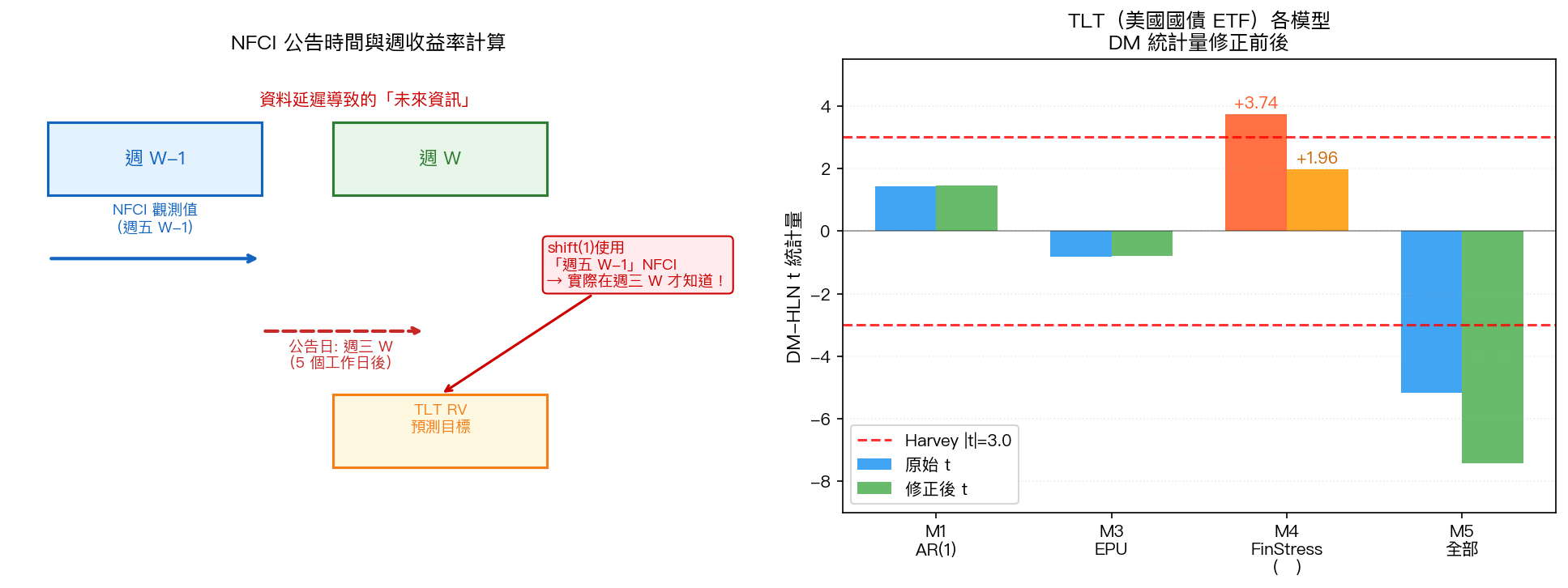 圖:TLT 四個模型的 DM t 統計量,修正前後對比。M4 金融壓力指數(橘色)從 +3.74 跌至 +1.96。
圖:TLT 四個模型的 DM t 統計量,修正前後對比。M4 金融壓力指數(橘色)從 +3.74 跌至 +1.96。
這類錯誤怎麼發生
FRED 資料的公告延遲並不難查,在 FRED 官網的 release calendar 上都有記錄。問題是,研究者在處理週頻資料時,習慣上 shift(1) 就算做了「避免看未來」的保護,卻沒注意到「shift(1) 週」在某些資料系列上,等於引入了 3 到 5 個交易日的延遲漏洞。
特別是以下幾個 FRED 系列的公布時序,使用週頻資料時要額外注意:
- NFCI / ANFCI :週五觀測值,下週三公布(5 個行事曆日)
- STLFSI4 :週五觀測值,下週四公布(6 個行事曆日)
- USEPU / WLEMU :每日更新,1 日延遲,週頻 shift(1) 基本安全
在月頻或季頻分析裡,這幾天的差距通常不影響,可以放心用 shift(1)。但在週頻預測,這幾天的差距剛好卡在週初的交易日,就會讓模型看到「當週尚未公布」的資訊。
這個問題是在另一個實驗(K1121)中被發現的,那個實驗在修正公告延遲後,策略績效沒有崩潰,但提醒了我們回去重看使用同樣 FRED 資料的 K1116 和 K1118。
結論
這次的發現沒有推翻什麼大方向,反而是確認了一件事: 在週頻波動率預測這個場域,VIX 類的市場隱含波動率指標,不需要外掛 FRED alt-data 也已經夠用 。金融壓力指數、不確定性指數不是沒用,只是它們的信號,在波動率已經被充分計入的情況下,貢獻接近零。
而 TLT 的那個例外,原本可以拿來說「美債有個特例」,修正後沒了。這讓整體結論更一致,跨資產的普遍性更高。
研究的結論沒有變弱,只是更乾淨了。
本文基於實驗 K1116b(腳本:experiments/k1116b/k1116b.py,結果:experiments/k1116b/k1116b_results.json)。引用數據:K1116(SPY)、K1118(GLD/TLT/BTC)原始實驗。數據來源:yfinance(ETF 價格)、FRED(USEPU/NFCI/ANFCI/STLFSI4);樣本期間 2018–2026 週頻,OOS 2023–2026(n=170 週)。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊