VIX 加進波動率模型,殘差會變得更「乾淨」嗎?SPY 七年實證的雙面結果
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
VIX 加進波動率模型,殘差會變得更「乾淨」嗎?SPY 七年實證的雙面結果
一個老問題:模型「對」了嗎?
每一個學過計量財務的人,都會被告知一件事:拿到一個波動率模型之後, 真正要看的不是它的「預測值」漂不漂亮,而是它「殘差」是不是乾淨的 。
什麼叫殘差乾淨?簡單說,就是把每天的報酬除以模型估計的當日波動率,得到一條叫做標準化殘差(z 值)的序列。如果模型把該抓的波動結構都抓走了,這條 z 值序列應該長得像一堆「沒有結構、沒有相關、分布對稱」的隨機數。如果還有結構殘留,例如平方項仍有自相關,或是分布尾巴特別肥,那就代表模型遺漏了某些東西。
這篇文章要回答的,正是一個近年很多研究者好奇的問題: 把 VIX 指數塞進波動率模型作為長期成分,能不能讓殘差變得比傳統的 GJR-GARCH 更乾淨?
直覺上,VIX 是市場自己對未來 30 天波動率的預期,它應該包含很多 GJR 從歷史報酬抓不到的資訊。但實證上會不會真的有效?我們在 SPY(標普 500 ETF)上跑了一整套殘差診斷,結果出乎意料: 答案是雙面的。
兩位主角:GJR-t vs A4f-t
這次比較的兩個模型:
- GJR-t :經典的 Glosten-Jagannathan-Runkle GARCH 模型,搭配 Student-t 分布的創新項。它只用歷史報酬建模,假設不對稱反應(壞消息影響大於好消息),是文獻中的 workhorse。
- A4f-t :屬於「乘法成分 GARCH」家族(Engle & Rangel 2008、Engle, Ghysels & Sohn 2013 那一脈)。把當日條件變異數拆成兩個相乘成分:
h_t = tau_t × g_t。其中tau_t由前一日的 VIX 平方驅動,扮演「長期慢變」的角色;g_t則是傳統 GARCH 遞迴,扮演「短期擾動」的角色。
設計上 A4f 顯然更「有彈性」,它多吃了 VIX 這個外生資訊。問題是,多吃資訊不代表診斷會變好。實證結果才是真話。
實驗設計
- 資產 :SPY(標普 500 ETF)
- 資料來源 :yfinance 日頻 OHLC,期間 2004-01-05 至 2026-04-10,共 5,602 個交易日
- 樣本外(OOS) :2019-01-02 至 2026-04-10,共 1,828 個交易日
- 滾動窗口 :2,000 日,每 63 日重估一次參數
- 隨機種子 :42(multistart 與抽樣可重現)
OOS 涵蓋 2020 COVID 崩盤、2022 通膨升息、2023 銀行危機與 2024-2025 多次回檔,是相當嚴苛的測試環境。
結果一:分布診斷,A4f 大勝
我們先看殘差分布的形狀有沒有貼近模型假設的 Student-t。下表是 1,828 個 OOS 標準化殘差的描述統計:
| 指標 | GJR-t | A4f-t | 哪個比較好 |
|---|---|---|---|
| 標準差 | 1.056 | 0.974 | A4f(更接近理想值 1.0) |
| 偏態 | -0.856 | -0.594 | A4f(負偏較輕) |
| 超額峰度 | 3.065 | 1.238 | A4f(少了 60%) |
| Jarque-Bera 統計量 | 938.8 | 224.2 | A4f(小 4.2 倍) |
| 中位數自由度(df) | 5.28 | 8.00 | A4f(尾巴較輕) |
最關鍵的數字是 超額峰度 。GJR-t 殘差的超額峰度是 3.07,意思是即使已經除以條件波動率,殘差分布仍比 Student-t 預期肥很多。A4f-t 把這個數字壓到 1.24, 減少了大約 60% 。
從 Student-t 自由度也能看出同樣的故事:GJR 估出來的中位數 df 是 5.28(很肥的尾巴),A4f 是 8.00(明顯較瘦)。換句話說, VIX 驅動的 tau 成分把原本被當作「肥尾」的部分,重新解釋為「條件變異數的時變」 ,留給創新項去吸收的尾部就少了。
兩個模型在 Kolmogorov-Smirnov 對 Student-t 分布的擬合上都未能完全達顯著水準的接受區(兩者皆呈現 p 極小)。但這對長樣本(N=1,828)的尾部診斷是常態現象,任何 parametric 假設在實際金融資料上都很難「通過」。 重點是相對好壞 ,A4f 在 5 個分布指標上全面領先。
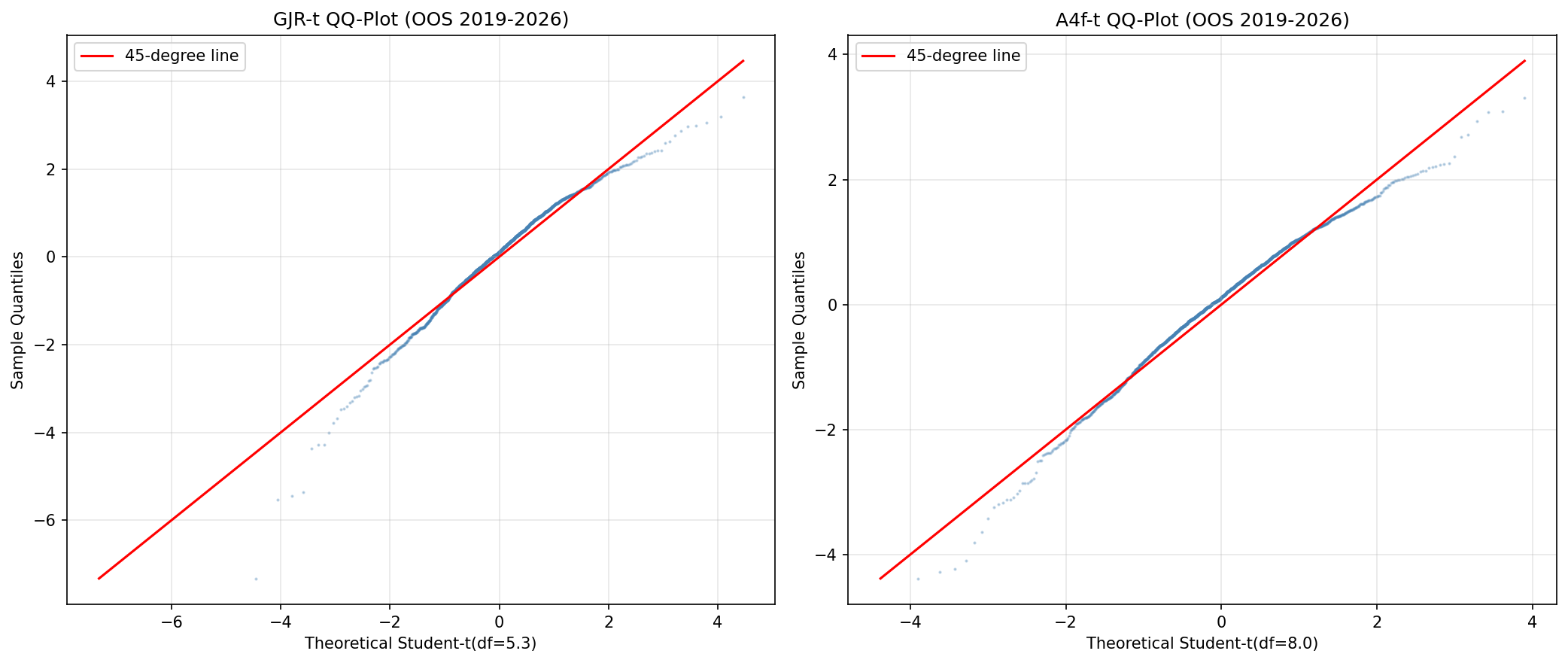
QQ 圖視覺上印證了這件事:A4f 殘差在尾部更貼近理論線,GJR 在 -3 以下的左尾明顯超出。
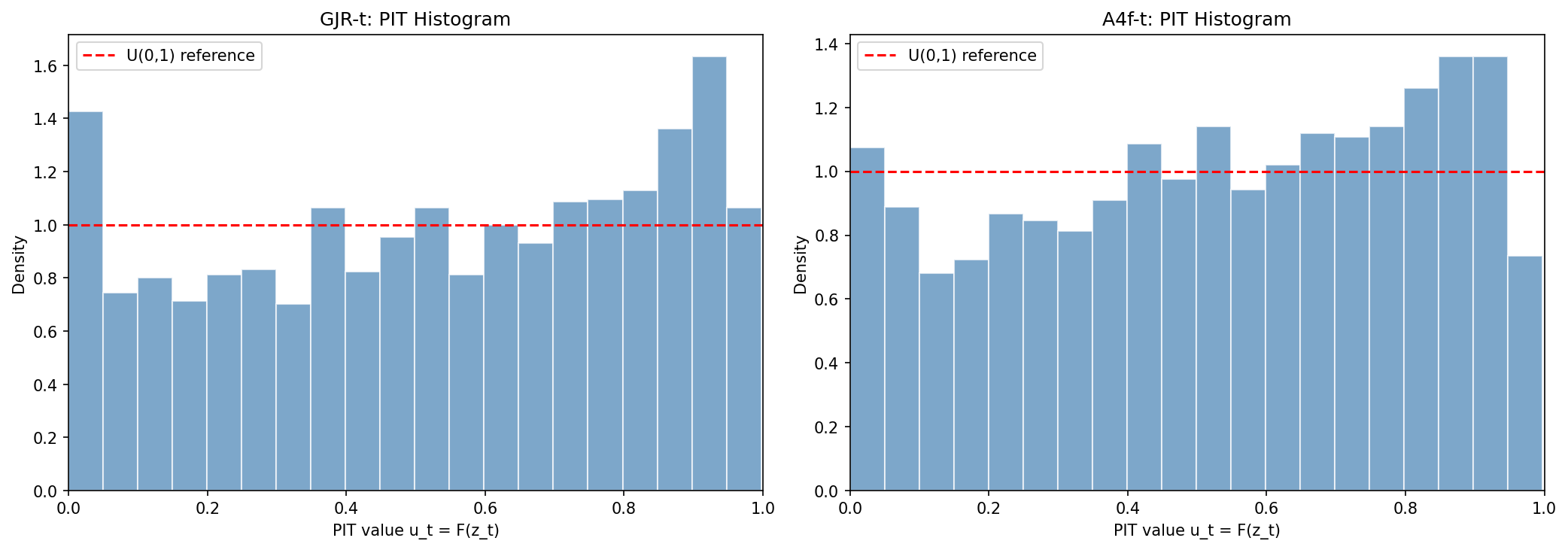
PIT(probability integral transform)直方圖則顯示,A4f 的均勻性比 GJR 略好,直方條更接近水平線,意味著機率密度估計更準確。
結果二:獨立性診斷,GJR 險勝
但故事還有另一面。我們再看殘差 有沒有殘留的 ARCH 結構 ——也就是 z 平方序列的自相關。如果模型乾淨抓走所有波動聚集,z² 應該是白噪音。
| 檢定 | GJR-t(p) | A4f-t(p) | 哪個好 |
|---|---|---|---|
| Ljung-Box(z², 1 期) | 0.310 | 0.070 | GJR |
| Ljung-Box(z², 5 期) | 0.636 | 0.228 | GJR |
| Ljung-Box(z², 10 期) | 0.787 | 0.544 | GJR |
| ARCH-LM(1) | 0.311 | 0.070 | GJR |
| ARCH-LM(5) | 0.621 | 0.210 | GJR |
| ARCH-LM(10) | 0.801 | 0.476 | GJR |
兩個模型在 5% 門檻下都通過所有 ARCH 檢定(所有 p 值都大於 0.05),意思是兩者的殘差都 沒有顯著殘留 ARCH 結構 。但 GJR 的 p 值系統性地比 A4f 高—— 這意味著 GJR 把短期波動聚集抓得更乾淨 。
這個結果其實合理。GJR 是一個「純 GARCH 遞迴」,每一個參數都在優化短期 ARCH 動態。而 A4f 把資訊分散到 tau 和 g 兩個成分,tau 由 VIX 平方驅動是「外生慢變」,留給 g 去抓的短期動態反而被稀釋了。
換句話說: A4f 用一部分短期 ARCH 抓取力,換到了長期分布形狀的改善 。沒有免費的午餐。
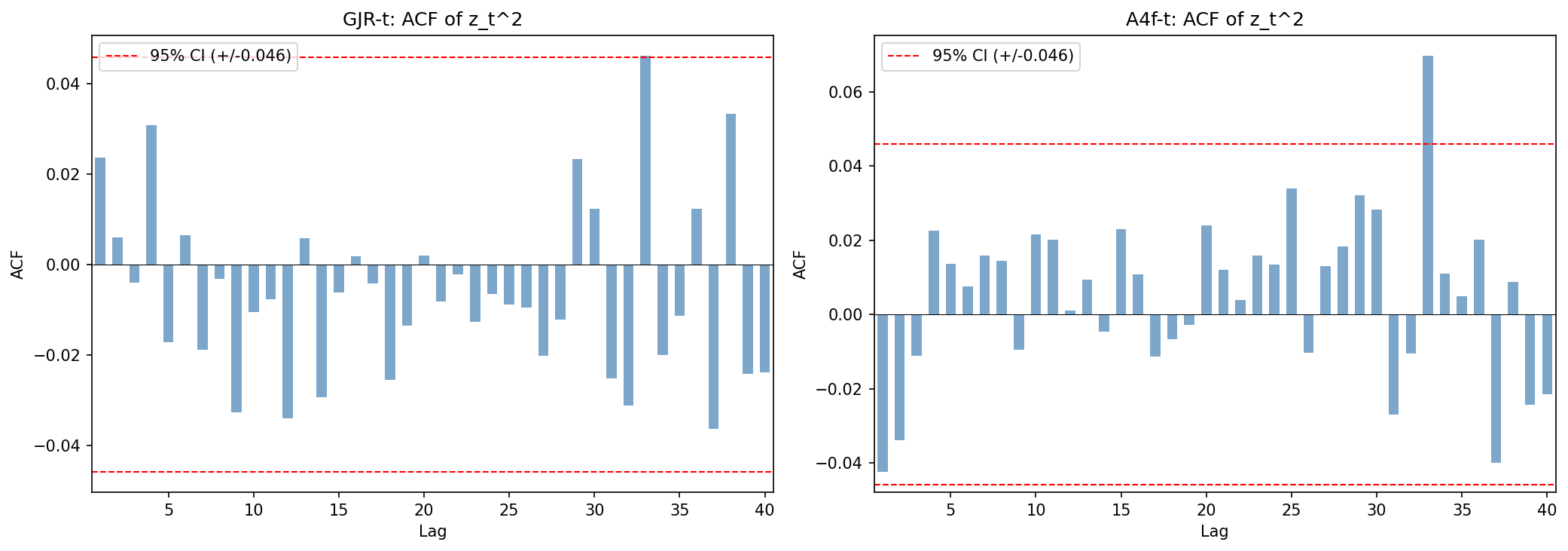
ACF 圖視覺上更直白:兩條線在低 lag 都壓在信賴帶內,但 GJR 的條形更貼近 0。
結果三:A4f 的內部診斷有個小麻煩
A4f 還有一個必須誠實報告的問題。它假設 g_t 序列的長期均值應該是 1(這樣 tau_t 才能扮演「總體變異水準」的角色),但 OOS 樣本實際估出來:
- E[g] = 0.306(理想值是 1.0, 距離達顯著水準的偏離 )
- g 的 1 階自相關 = 0.879(高度持續)
- tau 的變異係數 CV = 1.166(高度時變)
- tau 年化波動率範圍:13.8% 到 130.9%(涵蓋 COVID 等極端時期)
E[g] = 0.306 是乘法成分 GARCH 文獻中眾所周知的識別問題(Engle & Rangel 2008 即有討論):因為 omega 參數估得很小,g 收斂到一個小於 1 的水位。 這不會讓模型變成「錯的」 ——因為最終的 h_t = tau_t × g_t 仍然產生正確的總變異數,只是分解的「比例」不符合直覺解讀。
對學術寫作而言,這個 E[g] 偏離 1 的事實必須在限制章節說明清楚,不能掩蓋。
結果四:VIX 殘留相關,沒被消除
最後一個容易被忽略的細節。我們檢查標準化殘差和 VIX 同期值的相關性:
- GJR-t:corr(z, VIX) = -0.177
- A4f-t:corr(z, VIX) = -0.183
兩個模型的負相關幾乎一樣, A4f 並沒有把 VIX 的資訊「吸光」 。原因有兩層:
- tau_t 用的是「前一日」的 VIX 平方,但殘差 z_t 比較的是「當日」報酬。當日 VIX 的盤中變動可能含有 VIX(t-1) 之外的資訊。
- VIX² 是線性形式,但 VIX 與報酬的關係可能是非線性的(極端 VIX 跳升時的影響不只是平方項)。
這個發現提醒我們: VIX 不是萬靈丹 。即使把它放進模型結構裡,仍有一部分相關性會殘留。這是後續研究可以挖掘的方向(例如非線性 VIX 變換、VIX 短端 vs 長端的分解)。
整體評估:這是個雙贏雙輸的故事
把所有 7 個比較指標加總:
- A4f 勝 3 項(Jarque-Bera、KS-Student-t、PIT KS)
- GJR 勝 4 項(ARCH-LM 三個 lag、VIX 殘留相關)
從票數看 GJR 略勝,但這個計分方式偏袒 GJR——因為 ARCH-LM 的三個 lag 在實質上測同一件事(短期條件變異數的殘留),卻佔了 3 票。如果用「面向」來重新分組:
- 分布形狀 :A4f 明顯較好
- ARCH 結構移除 :GJR 略好(但兩者都通過嚴格統計檢驗門檻)
- 獨立性(z 序列) :兩者打平
- VIX 殘留相關 :兩者打平
對讀者實務的意涵
如果你關心的是 VaR / ES 之類的尾部風險指標 ,A4f 是更好的選擇,尾部 60% 的峰度被吸進去後,左尾分位數估計會比 GJR 穩定得多。對風險管理者而言,這直接影響資本準備金的計算。
如果你關心的是 短期波動率的點預測 (例如交易訊號、選擇權報價),GJR 的純 ARCH 遞迴可能反而更直接,因為它沒有把資訊外包給 VIX。對日內或短期應用,VIX 增益的 marginal value 偏低。
如果你做的是 學術論文寫作 ,A4f 的分布改善是更強的賣點,因為它對應到一個有趣的經濟故事:「VIX 把過去被當成肥尾的東西,重新解釋為 conditional variance 的時變」。這比「殘差比較沒結構」更有理論深度。
研究誠實聲明
這份比較有它的局限:
- 單一資產 :只在 SPY 上跑,多元資產(例如 0050.TW、QQQ、IWM)的結論可能不同。
- 單一參數化 :A4f 只試過 VIX² 的線性形式,未試 log-VIX、VIX 的 spline 函數、VIX 短端 vs 長端等。
- 靜態評分 :Jarque-Bera 在 N=1,828 時對任何小偏離都會大量爆炸,比較絕對 p 值意義有限,本文僅用相對統計量大小。
- E[g] 偏離 1.0 是 A4f 的已知識別問題,未影響預測值但影響參數可解讀性。
讀者在引用本實驗結果時,請以「在 SPY、2019-2026 OOS 期間、VIX² 線性形式下」為條件描述,不可推廣到其他資產類別或設定。
資料來源
- 資產報酬 :SPY ETF 日頻 OHLC,來自 yfinance(2004-01-05 ~ 2026-04-10,N=5,602)
- VIX 指數 :CBOE 公告值,由 yfinance 取得
- 樣本外期間 :2019-01-02 ~ 2026-04-10,共 1,828 個交易日
- 實驗代號 :K1045(完整資料、腳本、JSON 結果見
experiments/k1045/)
結論
把 VIX 放進波動率模型不是「免費的午餐」。在 SPY 七年的 OOS 測試上,VIX 增益帶來分布尾部的明顯改善(超額峰度減少 60%、Jarque-Bera 統計量小 4 倍),代價是對短期 ARCH 結構的吸收能力略遜於純 GJR。對風險管理應用,這個 trade-off 划得來;對短期點預測應用,未必。
更深一層的啟示是: 模型診斷不是單一指標的競賽,而是多面向的權衡 。下次有人告訴你某個新模型「全面更好」,記得問,它在哪一面比較好?另一面犧牲了什麼?這份實驗就是這個提醒最具體的證據。
延伸閱讀
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊