模型學不會的時候,最常做的事其實是少做決定
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
很多人聽到 machine learning,直覺都是同一個版本。
資料夠多、特徵夠細,模型應該就能比規則型策略更聰明,連「明天到底該不該開啟策略」這種事,也能學出一點門道。
這個實驗做的就是這個測試。
它拿 16 個市場特徵,包含 VIX 水位、期限結構、SPY 動能、波動度,還有 VT 近期表現,去預測一件很具體的事: 明天 VT 策略會不會比單純買進持有更好。
方法不算小氣。三種模型都上了,Logistic、XGBoost、Random Forest 全部做;資料從 2007-07-18 到 2025-12-31,共 4,645 筆日資料,另外還做了三段 cross-OOS 跟完整 walk-forward。
最後結論很簡單,也很不浪漫:
模型沒有學到一個穩定可用的開關。
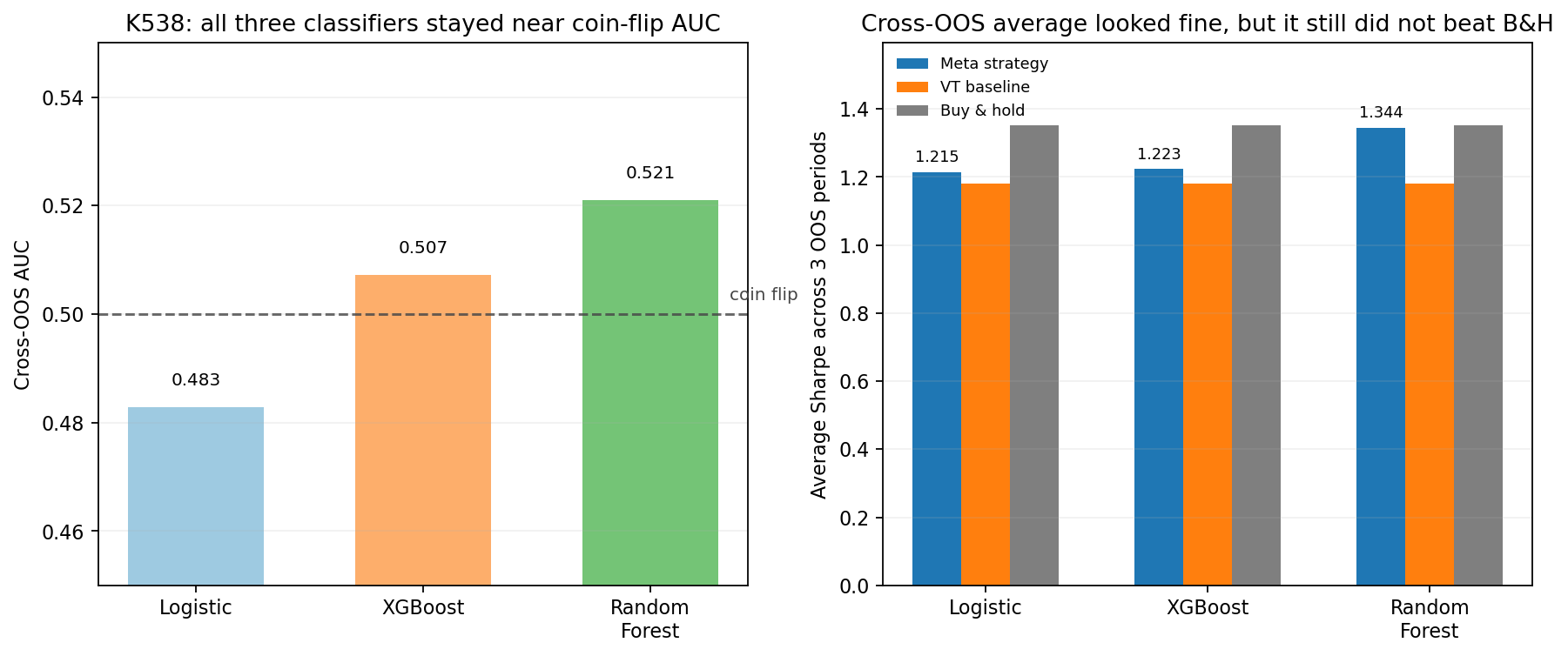
先看第一張圖左邊。
三個模型的 AUC 分別是:
0.4830.5070.521
都貼著 0.5 附近,差不多就是擲銅板等級。模型看到那些特徵後,對「明天 VT 會不會贏」這件事,幾乎沒有真正的辨識力。
右邊那張圖看起來比較容易誤導。因為三段外樣本平均下,Random Forest 的風險調整後表現分數有 1.344,比 VT 的 1.181 高一點,幾乎碰到買進持有的 1.351。
但問題是,這種平均值沒有穩到能信。
- 它只在
3段外樣本裡贏 VT2次 - 對買進持有是
0/3 - 三個模型都沒有形成一致勝率
所以,你不能把它解讀成「模型已經找到穩定優勢」。比較接近的說法是: 短區間裡偶爾看起來不錯,但沒有形成可以複製的規律。
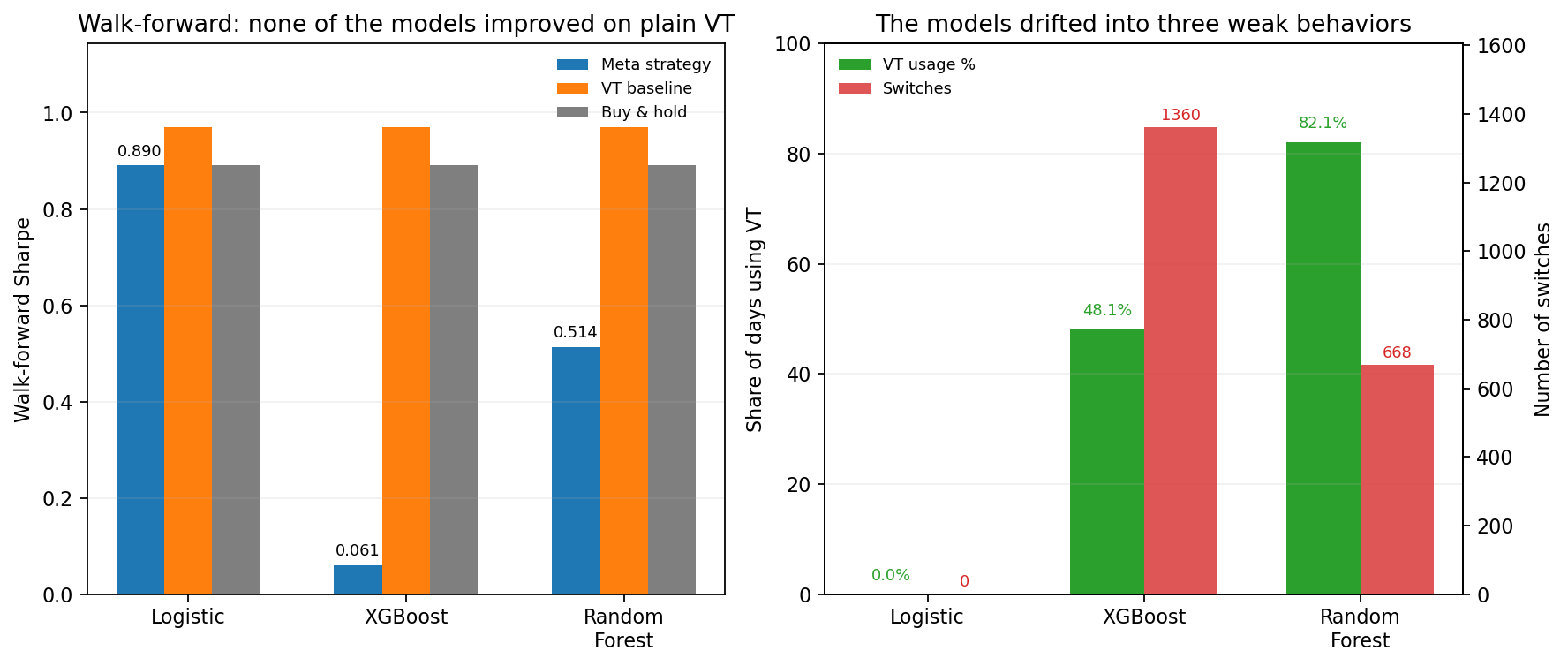
真正把故事講清楚的是第二張圖。
一拉到完整 walk-forward,三個模型立刻露出本性。
Logistic 最極端。它最後幾乎完全不啟用 VT,vt_usage_pct = 0.0%,切換次數也是 0。白話就是:模型想了半天,最後學到的答案是「乾脆整段都買進持有」。
XGBoost 走另一個方向。它大概有 48.2% 的日子啟用 VT,但切換了 1,360 次,完整測試裡的風險調整後表現只剩 0.061,比 VT 的 0.969 差非常多。這不是聰明切換,比較像是 來回忙了一大圈,反而把表現磨掉。
Random Forest 看起來最像正常人。它有 82.1% 的日子留在 VT,切換 668 次,完整測試裡的分數是 0.514。問題是,這樣還是輸給 VT,也沒有贏過買進持有。
所以這個實驗最值得記住的,不是某個模型差一點點贏。更重要的是,它們最後分別退化成三種常見動作:
- 乾脆別切,直接變成買進持有
- 一直切,但沒切出好結果
- 大部分時間照舊待在 VT,等於沒多學到多少新東西
這和實驗裡另一個數字很一致:16 個特徵跟「明天 VT 會不會贏」的相關幾乎都趨近零,最大也只有 |r| < 0.02。
意思不是機器學習很差。
比較像是這個問題本身太吵。VT 的優勢如果來自比較長期的 VIX 均值回歸,那麼你硬要用日頻資料去抓「明天開還是關」,模型很可能只會學到一堆不穩定的小噪音。
這也是這篇實驗最有價值的地方。它沒有證明模型不行,只是提醒你:
如果一個決策本身沒有夠強的可預測訊號,再多模型常常也只會把你帶到「少做決定」或「亂做決定」這兩個方向。
對投資人來說,這反而是很實用的結果。因為它讓你知道,有些策略的價值,可能根本不在每天判斷要不要開關,而是在你能不能接受它長期運作時的邏輯。
本文基於實驗 K538(腳本:experiments/k538/k538_meta_labeling.py,結果:experiments/k538/k538_meta_labeling_results.json)。資料來源為 yfinance 的 SPY、^VIX、^VIX3M、TLT、GLD,期間 2007-07-18 至 2025-12-31,共 4,645 筆樣本。設定為預測「次日 VT 是否優於買進持有」的二元分類,含三段 cross-OOS、22 天 embargo 與 10 bps 交易成本。
更正啟事(2026-06-15 補):本文的定性結論(三個模型都退化為買進持有 / 過度切換 / VT 鎖死,沒有學到穩定可用的開關)經獨立程式碼審查後成立;但兩項實驗設計細節需要對讀者誠實揭露:(1)「22 天 embargo」實際以日曆月對齊,跨交易日為 20–21 列,略短於宣稱值;(2) 10 bps 交易成本以「日變動標誌切換」乘 1 計,未按實際倉位變動比例計算,因此切換成本被低估。這些細節讓模型在數字上「多被嫌棄一點」,並不改變沒有預測力的結論方向。後續會在追蹤實驗中修正並重新計算 walk-forward 區段的 Sharpe / MDD。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊