把兩個看起來都不錯的模型混在一起,為什麼最後還是贏不了最強那個?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
把兩個看起來都不錯的模型混在一起,為什麼最後還是贏不了最強那個?
投資研究裡有個很直覺的想法:
如果兩個模型各有優點,那把它們平均、加權,甚至讓系統自己學權重,理論上應該更穩、更準。
這個想法聽起來很合理,所以很多人會自然以為:
單一模型很強,組合模型應該更強。
但 K1315 跑出來的答案剛好相反。
在 SPY 這條線上,把「只看歷史波動」和「加入 VIX 的模型」混在一起之後,結果並沒有變更好。最好的那個,還是原本就最強的 HAR-VIX 單一模型。
這次到底在比什麼
這份實驗做的不是再發明新模型,而是問一個更務實的問題:
既然 HAR-VIX 已經比純歷史模型好,那再把兩者組合起來,能不能再往前推一步?
測試對手有五個:
- 只看歷史波動的基準模型
- 加入 VIX 的模型
- 兩者直接 50/50 平均
- 根據最近表現動態加權
- 用經典 OLS 組合法自動估權重
資料是 SPY,樣本外期間是 2019-01-02 到 2024-12-30,共 1,509 個交易日。
排名第一的,的確不是單模
如果你只看表面排名,會覺得組合模型好像有戲。
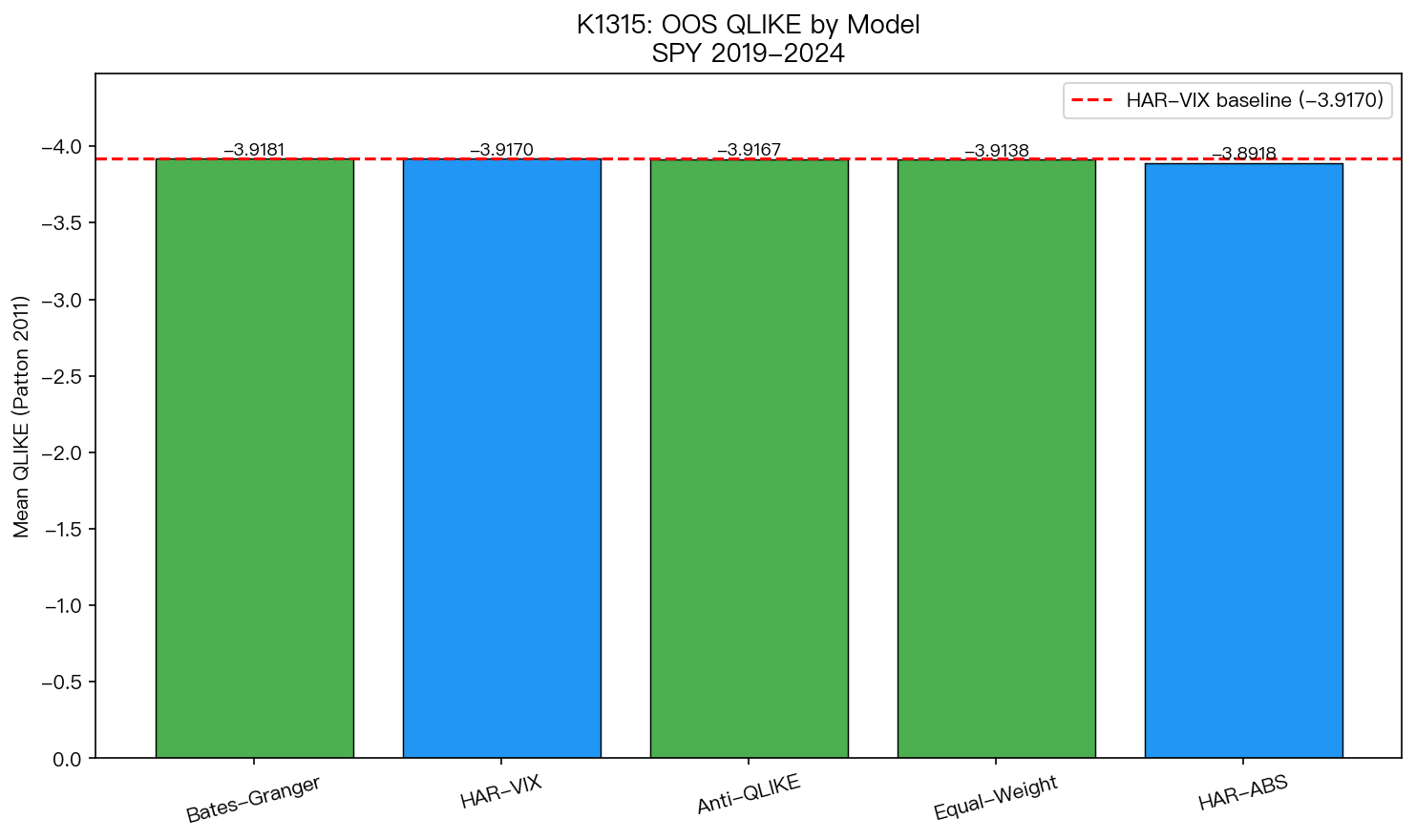
五個模型的樣本外誤差分數是:
| 模型 | 誤差分數 |
|---|---|
| Bates-Granger 組合 | -3.9181 |
| HAR-VIX | -3.9170 |
| 動態加權組合 | -3.9167 |
| 50/50 平均 | -3.9138 |
| 純歷史基準 | -3.8918 |
乍看之下,第一名確實是組合模型,而且還比 HAR-VIX 稍微低一點。
但真正重要的不是「誰排第一」,而是:
這個差距大到足以當真嗎?
答案是: 沒有。
最關鍵的一句話:差距小到不能算真的贏
這份實驗用了很嚴格的兩模型比較檢定。結果是:
- 動態加權 vs
HAR-VIX:1.08 - 50/50 平均 vs
HAR-VIX:1.04 - Bates-Granger vs
HAR-VIX:-0.69
這些數字都離「可以當真」的門檻很遠。
白話講就是:
雖然組合模型在表格上有時排第一,但那個領先幅度小到你不能說它真的比 HAR-VIX 更準。它比較像是同一個水準上的隨機前後,而不是明確升級。
系統最後幾乎把全部權重都押回 VIX
這篇最有意思的地方,不是排名,而是動態加權模型最後怎麼選。
實驗裡有一個會隨時間調整權重的版本。它理論上可以在:
- 歷史波動模型
- VIX 模型
之間自由分配。
結果跑到最後,權重大概變成:
- 歷史波動模型:
0.00004 - VIX 模型:
0.99996
幾乎等於全部壓在 HAR-VIX 上。
這個畫面很有說服力。因為它不是研究者主觀說「VIX 看起來比較重要」,而是讓系統自己根據一路上的表現做選擇,最後它還是把答案收斂到 VIX 那邊。
這代表什麼
最直白的解讀是:
在這段 SPY 樣本裡,VIX 提供的訊息已經夠多了。
你把純歷史波動模型再疊上去,不是完全沒幫助,但幫助小到不足以形成可確認的增量。
換個比喻比較好懂。
假設你要猜明天會不會下大雨,手上有兩個資訊來源:
- 過去幾天的天氣
- 今天的雷達雲圖
如果雷達雲圖已經把明天的風險講得很完整,那你再把過去幾天的資料混進來,通常不會讓答案忽然變得更高明。你只是把一個本來就很強的訊號,又拿去跟一個比較弱的訊號平均。
結果常常不是更準,而是被稀釋。
這篇實驗最值得記住的教訓
K1315 很適合拿來提醒一件常見誤解:
組合,不會自動創造新資訊。
如果兩個模型看到的是差不多的東西,而且其中一個已經把訊號吸得差不多了,那把它們混起來,多半只是讓表達方式更複雜,不會讓結果真的升級。
這也是為什麼這篇的結論不是「組合模型沒用」,而是比較精確的版本:
- 組合模型沒有比最強單模差很多
- 但也沒有強到足以宣告超越
- 而且動態權重最後幾乎全部回到
HAR-VIX
所以最務實的讀法是: 如果你已經有 HAR-VIX,再往上疊這些組合法,至少在這段資料裡沒有額外價值。
對實務上有什麼用
如果你在做波動率預測、風險控制、或任何需要先估明天風險大小的流程,這篇給的提醒很簡單:
- 不要因為「組合」聽起來更高級,就預設它更好。
- 先確認最佳單模本身是不是已經把主要訊號抓住了。
- 如果組合後只多出一點點表面排名優勢,但沒有穩到能驗證,就不要急著把系統複雜化。
對一般投資人來說,這其實是個好消息。因為它代表:
很多時候,最值得用的不是最花的做法,而是那個已經夠強、又夠簡單的做法。
資料來源
本文基於本平台一份 SPY 波動率組合預測實驗。資料來源:yfinance,資產 SPY 與 VIX,樣本內期間 2005-01-04 至 2018-12-31,樣本外期間 2019-01-02 至 2024-12-30,共 1,509 個交易日。比較對象包括歷史波動基準模型、HAR-VIX、等權平均、動態加權與 Bates-Granger 組合;評估方式為樣本外預測誤差分數與兩模型比較檢定。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊