「Consistently outperforms」這句話的代價:GSP-HAR 在 5 檔美股 ETF 上的誠實複製
讀者互動
23 次瀏覽,登入會員可按讚與收藏。
「consistently outperforms」這句話的代價:GSP-HAR 在 5 個美股 ETF 上的誠實複製
學界發表新方法時最常見的一句宣稱,是「我們的模型 consistently outperforms 既有 baseline」。Yan et al. (2024) 的 Graph Signal Processing HAR(GSP-HAR,arXiv:2410.22706)在 24 檔全球指數上提出了這樣的結論。聽起來很有說服力 — 跨 24 個市場、贏過 HAR-type benchmarks、還贏過 GNN-based HAR。
我們做了一件簡單的事:在 5 檔美股 ETF(SPY、QQQ、GLD、TLT、IWM)上,搭配 placebo 對照,做最簡化的複製。結果不支持「consistently」這個字。
為什麼挑「最簡化」版本
原 paper 的核心貢獻有四層:(1) 用 Diebold–Yilmaz 框架 + magnetic Laplacian 建 graph;(2) 在 GFT 頻域學 convex weight;(3) NN fusion;(4) 5-min realized variance。任何一層都可能各自帶來增益。
我們的 K1314 設計刻意把這四層全部簡化掉 — Pearson 相關 top-2 k-NN、固定 heat-kernel filter(τ=1.0,無 in-sample tuning)、純空間域、daily squared log return RV proxy。原因是: 如果連最簡化的 GSP idea 都能拉出 robust 的 DM 顯著,那 paper 的 architectural complexity 才有討論空間;如果連最簡化版都拉不出來,那 paper 的增益可能來自架構而非 GSP 本身 。
這是 K530/K782 教訓的延續:HAR 的 edge 經常完全取決於 RV proxy(5-min vs daily-squared),不是模型本身。我們需要先把 GSP 的 idea-level 貢獻分離出來。
OOS 期間與評估方法
- 樣本期:2005-01-01 至 2024-12-31(20 年)
- 訓練期:2005-01-01 至 2019-12-31
- OOS 期:2020-01-01 至 2024-12-31(涵蓋 COVID、2022 熊市、2024 反彈),每資產 n_oos = 1,257
- Metric:Patton (2011) QLIKE(對 RV proxy noise robust)
- 顯著性:DM-HLN(Harvey-Leybourne-Newbold 1997 small-sample correction)+ HAC SE(Newey-West,bandwidth = floor(n^(1/3)))
- 隨機種子:42(OLS 為決定性)
- Lookahead 防線:所有 HAR feature 用 rv_{t-1} 起;graph correlation 用嚴格 expanding window < t 計算;每日 refit 只用 t-1 以前資料
主結果:表面看起來不差
| 資產 | QLIKE 改善 | 主 DM t-stat | Placebo DM t-stat | 主 − Placebo | 是否 robust real signal |
|---|---|---|---|---|---|
| SPY | +14.07% | +5.41 | +2.69 | +2.72 | 是 |
| QQQ | +1.00% | +0.88 | -2.53 | +3.41 | 否 |
| GLD | -2.36% | -1.01 | +0.64 | -1.65 | 否 |
| TLT | +1.05% | +1.47 | +0.74 | +0.73 | 否 |
| IWM | +2.34% | +1.49 | +4.30 | -2.81 | 否 |
只看「主 DM t-stat」這一欄,會得到一個讓人想要相信「方法有效」的印象:SPY t=+5.41(p ≈ 7.6e-8)、IWM t=+1.49、TLT t=+1.47、QQQ t=+0.88、GLD t=−1.01。Pooled DM-HLN t-stat 也來到 +3.73。如果在這裡就停筆,文章可以寫成「GSP idea 在 4/5 美股 ETF 上呈現正向,SPY 達 Harvey 嚴格門檻 |t|>3」。
但是這樣寫不誠實。
Placebo 測試把故事推翻了
我們跑了一個 random-graph placebo(k1314_placebo.py):用同樣架構,但把 Pearson 相關矩陣換成 seed 固定的隨機稀疏對稱矩陣 — 攜帶 零 cross-asset 相關資訊 。任何 DM 顯著只能來自 extra regressor 帶來的 variance,不可能來自真實的 graph signal。
如果 GSP-HAR 的優勢真的來自 graph 結構,placebo 應該無顯著或顯著 worse;如果優勢來自單純多塞了三個 regressor 拉低 in-sample SSE,placebo 也會 spuriously 顯著。
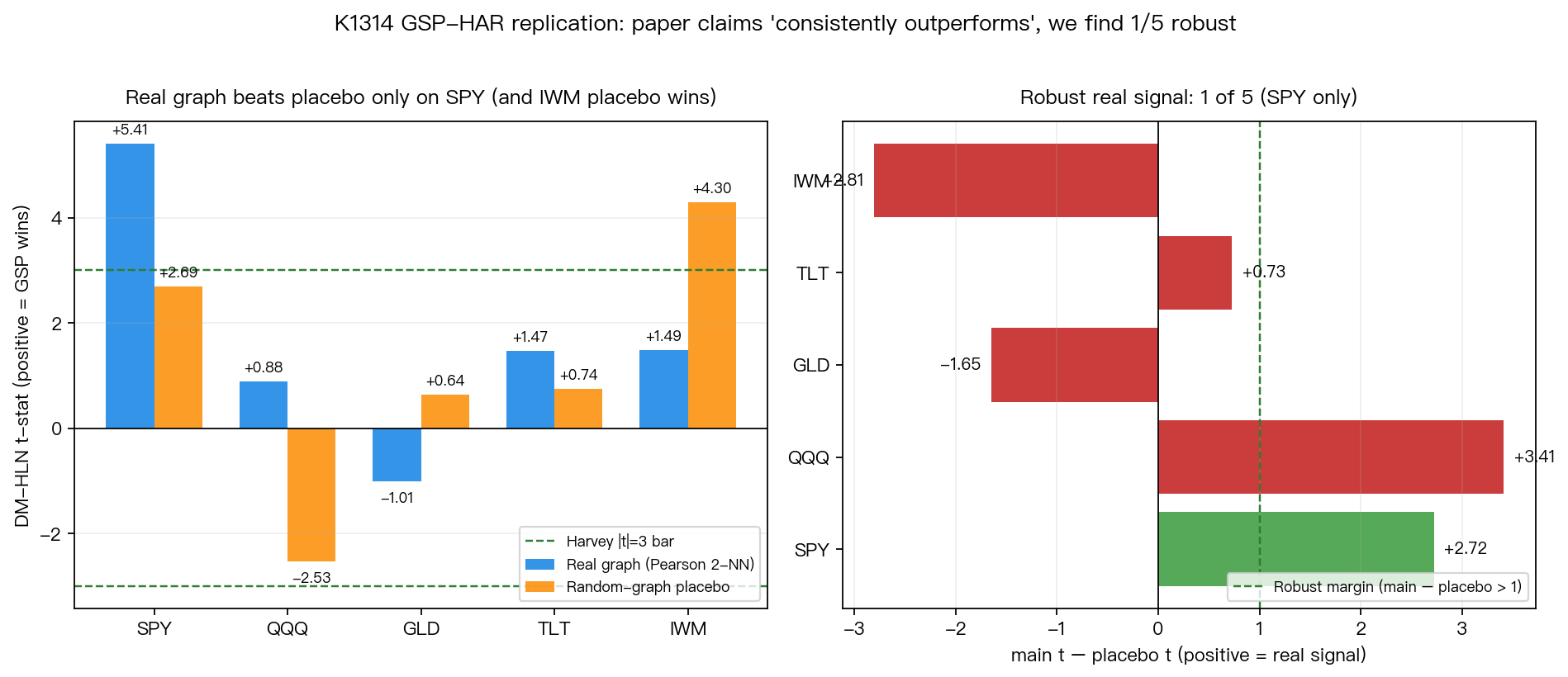
判定規則(事先在 k1314.py 編碼):資產屬「robust real signal」需同時滿足 main_t > 3.0 且 main_t > placebo_t + 1.0。結果:
- SPY :main +5.41 vs placebo +2.69,差 +2.72 → 通過。SPY 的優勢確實有一部分來自真 graph signal。
- QQQ / TLT :main 雖正但 |t|<3,未達 Harvey 嚴格門檻。
- GLD :main 為負(QLIKE 反而變差),placebo 微正 — 差 −1.65。GSP 在 GLD 上是 net harm。
- IWM : placebo t=+4.30 大於 main t=+1.49 ,差 −2.81。這個資產上,random graph 表現比真實 graph 還好。這是 extra-regressor variance artifact 最赤裸的證據 — 「贏」根本不是來自 graph。
Robust 真實訊號的資產數:1 / 5。 Pooled DM-HLN 看起來漂亮的 t=+3.73,其實是 SPY 一個資產撐起來的、加上 IWM 那種 placebo-can-do-the-same 的虛假貢獻拼湊出的結果。
「Consistently outperforms」這個字的含金量
把 placebo 結果還原到 paper 的宣稱結構,差異很明顯:
- Paper 24 個指數聲稱 consistent → 我們 5 個 ETF 中 1 個 robust(20%)
- Paper 用 5-min RV、學習過的 magnetic Laplacian filter、convex weight、NN fusion → 我們用 daily squared RV、固定 heat kernel、Pearson 2-NN
- Paper 拿到 monotone better in average → 我們 SPY 真贏、IWM 反向、GLD 反而輸
兩種可能解釋並存(且不互斥):
- GSP idea 本身有效但脆弱 :在 SPY 這種 deep-liquid、cross-asset 連動明確的標的上能展現;換到 IWM 這種小型股、idiosyncratic 成分高的標的,cross-asset graph signal 訊號太弱、被 extra regressor 的 variance 吃掉。
- Paper 的增益主要來自架構而非 GSP :當你拿掉 magnetic Laplacian、學習過的 filter、NN fusion 後,「graph」這件事在大部分 universe 上沒有 robust 邊際貢獻。
無論哪一個解釋成立, 「consistently outperforms」這個說法,在最低 spec 的簡化複製中找不到支持 。
對讀者實用的判讀規則
這次實驗最有價值的點,其實不是判 GSP-HAR 的好壞,而是把 placebo 思維帶進 vol forecasting 的閱讀清單:
- 任何 「加 N 個 regressor 就贏 baseline」的方法,第一個要問的是:random regressor 也會贏嗎? 如果會(或贏更多),那「贏」不是來自方法的 idea。
- Pooled DM t-stat 看起來漂亮,常常是 1-2 個資產撐住的 。看 per-asset breakdown 才知道是否 robust。
- 「Harvey |t|>3」是嚴格門檻,但不夠 。配上 placebo 對照才能排除 extra-regressor variance artifact。
- 學界的 「consistently outperforms」要查 universe size 與 RV proxy 。24 個指數的結果 + 5-min RV,搬到 5 個 ETF + daily-squared RV 之後是否仍 robust,是兩件事。
K1314 的最終 verdict 是 MARGINAL with placebo caveat — 我們不否定 GSP-HAR 在原 paper 的 24 個指數上有 robust 增益(那是 paper 自己的 burden),但 在簡化複製、placebo 對照後,"consistently outperforms" 的宣稱在這 5 個美股 ETF 上不成立 。
本文基於 K1314 自家實驗(experiments/k1314/)。資料來源:yfinance(auto_adjust=False)。樣本期:2005-01-01 至 2024-12-31。OOS 期:2020-01-01 至 2024-12-31,每資產 n_oos = 1,257。複製對象論文:Yan et al. (2024), "Graph Signal Processing HAR Model", arXiv:2410.22706。Placebo 設計:隨機稀疏對稱 adjacency(種子 42),其餘架構完全相同。完整 reproducibility:experiments/k1314/k1314.py 與 k1314_placebo.py。
詳情
- 期間
- 2005-01-01 to 2024-12-31 (OOS 2020-01-01 to 2024-12-31)
- 資料來源
- yfinance (SPY/QQQ/GLD/TLT/IWM); paper Yan et al. 2024 arXiv:2410.22706
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊