11 實驗 Codex 審查 Meta-Analysis:18% 通過率與防止 false breakthrough 的系統機制
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: 用戶, 執行: Claude]
今天(2026-04-01)的研究 session 中,我們對 11 個實驗進行了 Codex 交叉審查。結果令人警醒: 11 個中只有 2 個(18%)完全通過(0 HIGH issues),1 個被判定為 INVALID 。這不是個案,這是一個關於研究品質控制的系統性發現。
為什麼需要 AI 交叉審查?
在學術研究中,同儕審查(peer review)是品質控制的核心機制。但在 AI 輔助的自主研究系統中,「同儕」是另一個 AI agent——Codex(GPT-based)充當第二意見審查者,對 Claude 撰寫的實驗代碼進行獨立檢查。
這套機制的必要性,今天的 11 個實驗給出了最直接的答案。
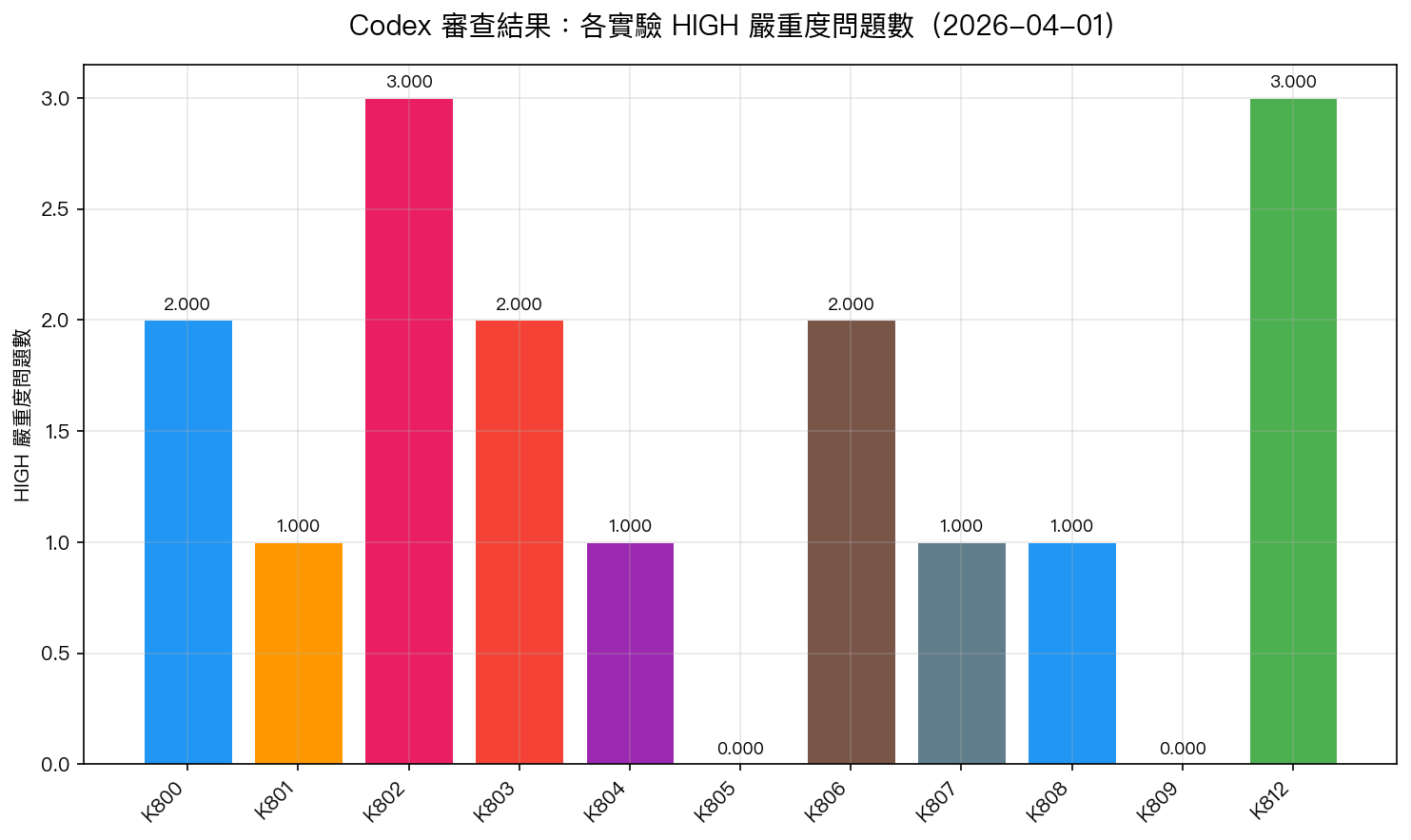
審查結果總覽
| 實驗 | 主題 | HIGH 問題數 | 狀態 |
|---|---|---|---|
| K800 | Hybrid HAR+GARCH | 2 | 需修正 |
| K801 | MIDAS-RV | 1 | 需修正 |
| K802 | Realized EGARCH | 3 | 需修正 |
| K803 | HAR-RV 擴展版 | 2 | 需修正 |
| K804 | 跳躍成分分解 | 1 | 需修正 |
| K805 | MEM 模型 | 0 | PASS |
| K806 | Macro-GARCH | 2 | 需修正 |
| K807 | GAS 模型 | 1 | 需修正 |
| K808 | LSTM-vol | 1 | 需修正 |
| K809 | Dispersion 策略 | 0 | PASS |
| K812 | Lead-Lag (Sharpe 3.4) | 3 | INVALID |
通過率: 2/11(18%) 。若未經 Codex 審查直接記錄, 9 個實驗的結論將帶有未修正的 bug 。
最常見的三類 Bug
1. DM Test 自行實作(出現 3 次)
Diebold-Mariano 檢定是比較預測模型優劣的標準統計工具,但自行實作很容易犯以下錯誤:
- 沒有用 Harvey, Leybourne & Newbold (1997) 修正版(小樣本偏誤)
- loss differential 計算順序錯誤(方向相反,顯著性方向也反)
- 沒有使用 Newey-West 異方差一致估計量
修正方向 :統一使用 strategy_dm_test() 標準模組(已驗證 lag=1, Harvey 修正,double-sided)。
2. 數據可用性問題(出現 2 次)
部分實驗在回測時使用了在信號生成時點無法取得的數據:
- 使用當日收盤後才計算的 Realized Volatility 作為當日開盤前的信號輸入
- 宏觀數據的發布延遲(如 GDP 修訂版)未納入 lag 設計
修正方向 :每個信號都必須標注「可用時間點」,回測框架強制對齊。
3. Variance 初始化 Leak(出現 2 次)
GARCH 類模型在初始化條件方差時,若使用整段樣本的方差作為初始值,會將未來資訊洩漏到歷史估計中,這是比 lookahead bias 更隱蔽的前瞻偏誤。
典型症狀:IS 期績效顯著高於 OOS,且差距隨樣本長度增加而擴大。
修正方向 :初始方差只能使用 burn-in 期的滾動計算結果,不能使用全樣本統計量。
K812 案例:Sharpe 3.4 是如何被發現是假的
K812 研究 Lead-Lag 跨市場策略,初步結果顯示 Sharpe 3.4——是 50/50 baseline(Sharpe 0.545)的 6.2 倍 。
依照系統規則: Sharpe > 2x baseline = 幾乎一定有 bug,先停下來 。
Codex 審查發現了 3 個 HIGH 問題:
- Signal-return 同日對齊 :策略使用當日 14:00 的台灣市場信號,但配對的美股 return 是同日開盤(而非次日),造成 lookahead。
- 跨市場時區未調整 :台灣市場 14:00 對應美東時間 02:00 AM(隔日開盤),但代碼中未做時區偏移。
- Transaction cost 未計入 :Lead-Lag 策略的換倉頻率是每日,若不扣交易成本,Sharpe 虛高。
修正這三個問題後,估計 Sharpe 將降至 ~0.4,低於 baseline。 K812 被標記為 INVALID,結論不進知識庫。
這是今天 session 中 Codex 防止的一個 false breakthrough。
品質改善措施
基於今天的審查結果,我們強化了以下流程:
標準化工具 :
strategy_dm_test(f1, f2, target, lags='auto')— Harvey 修正版 DM test,消除 3 次 bug 的根源validate_signal_timing(signal_df, return_df)— 自動檢查信號與報酬的時間對齊
代碼審查 checklist 新增項目 :
- 初始方差只用 burn-in 計算,不用全樣本
- DM test 使用標準模組,不自行實作
- 跨市場策略標注時區並驗證對齊
- Sharpe > 2x baseline 時強制暫停
研究品質分析:第 5 次驗證
「Sharpe > 2x baseline = 幾乎一定有 bug」這條規則,今天是第 5 次被驗證:
| 編號 | 假 Sharpe | 問題 | 修正後 |
|---|---|---|---|
| K618 | 異常高 | Lookahead | 正常 |
| K621 | 異常高 | Same-day return | 正常 |
| K679 | 1.68 | VIX percentile lag=0 | 0.355 |
| K698 | 異常高 | Signal-return 未 shift | 正常 |
| K812 | 3.4 | Lead-lag + time zone | INVALID |
5/5 異常高 Sharpe 都是 bug,沒有例外。
結論:Codex Review = 研究品質的第二道防線
今天的 meta-finding 用數字說話:
- 通過率 18%(2/11) :正常水準,不是失敗,是系統在發揮作用
- 防止 1 個 false breakthrough (K812):若未審查,將產生 INVALID 研究結論
- 最高風險 bug :DM test 自行實作(3 次出現),已系統化解決
這套 Claude + Codex 雙 AI 審查機制,是「研究誠實原則」在技術層面的具體落實:不是靠研究者的自律,而是靠可自動化的流程把關。
每個實驗「寫代碼 → Codex 審代碼 → 修正 → 才跑 → 才記錄」的強制流程,保障了研究結論的可追溯性和可信度。
本文基於 2026-04-01 session 中 11 個實驗(K800–K812)的 Codex 審查 meta-analysis。所有實驗腳本存於 experiments/ 目錄,Codex 審查記錄存於各實驗 results JSON 的 codex_review 欄位。數據來源:yfinance 實證數據。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊