我以為發現了一個訊號,其實只是資料在自己對話——「重疊窗口」的陷阱
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: Claude, 執行: Claude] 我們原本以為自己發現了一個新的股價規律,統計上看起來非常漂亮。但在換用更嚴格的檢驗方法後, 訊號縮水成原本的三分之一以下 ,漂亮的規律幾乎消失。這不是模型錯,也不是資料錯,是一個很技術、但每個看回測的人都該知道的陷阱: 重疊窗口 。
想像你在路上問人家對你頭髮的意見
你新剪了一個髮型,想知道大家覺得怎麼樣。
- 版本 A :你問 100 個 不同的 陌生人。
- 版本 B :你問 同一個朋友 100 次。
兩個版本最後都收集到 100 個意見。但哪一個比較可信?
答案很明顯: 版本 B 其實只有 1 個人的意見被重複 100 次 。你以為有 100 個獨立看法,實際上只有 1 個。
金融研究裡有一個幾乎一模一樣的錯誤,叫做 重疊窗口(rolling window overlap) 。
滾動窗口是什麼、問題出在哪
很多研究會用「滾動窗口」來算時間序列的特性。例如:
- 用過去 24 個月的資料算一次平均。
- 把窗口往前移一個月,再算一次。
- 再往前移一個月,再算一次。
這樣做看起來很棒,你每個月都有一個新的數字,一年有 12 個數字,十年有 120 個數字。
但陷阱是 :相鄰兩個月算出來的數字,其實用了 23 個月 完全一樣的資料 ,只差 1 個月的新資料。換句話說,每個「新數字」其實跟前一個幾乎一樣。
這就跟「問同一個朋友 100 次」一樣,看起來你有很多觀察值,實際上大部分是重複的。你會因此 嚴重高估 自己訊號的可信度。
我們實測:修正前 vs 修正後
我們原本有三檔台股,用滾動窗口算出來的訊號非常強,統計上像是「100% 確定」有東西。
接著我們改用 區塊自助抽樣 (block bootstrap,這是處理這類問題的黃金標準方法),把資料切成不重疊的區塊重新檢驗。
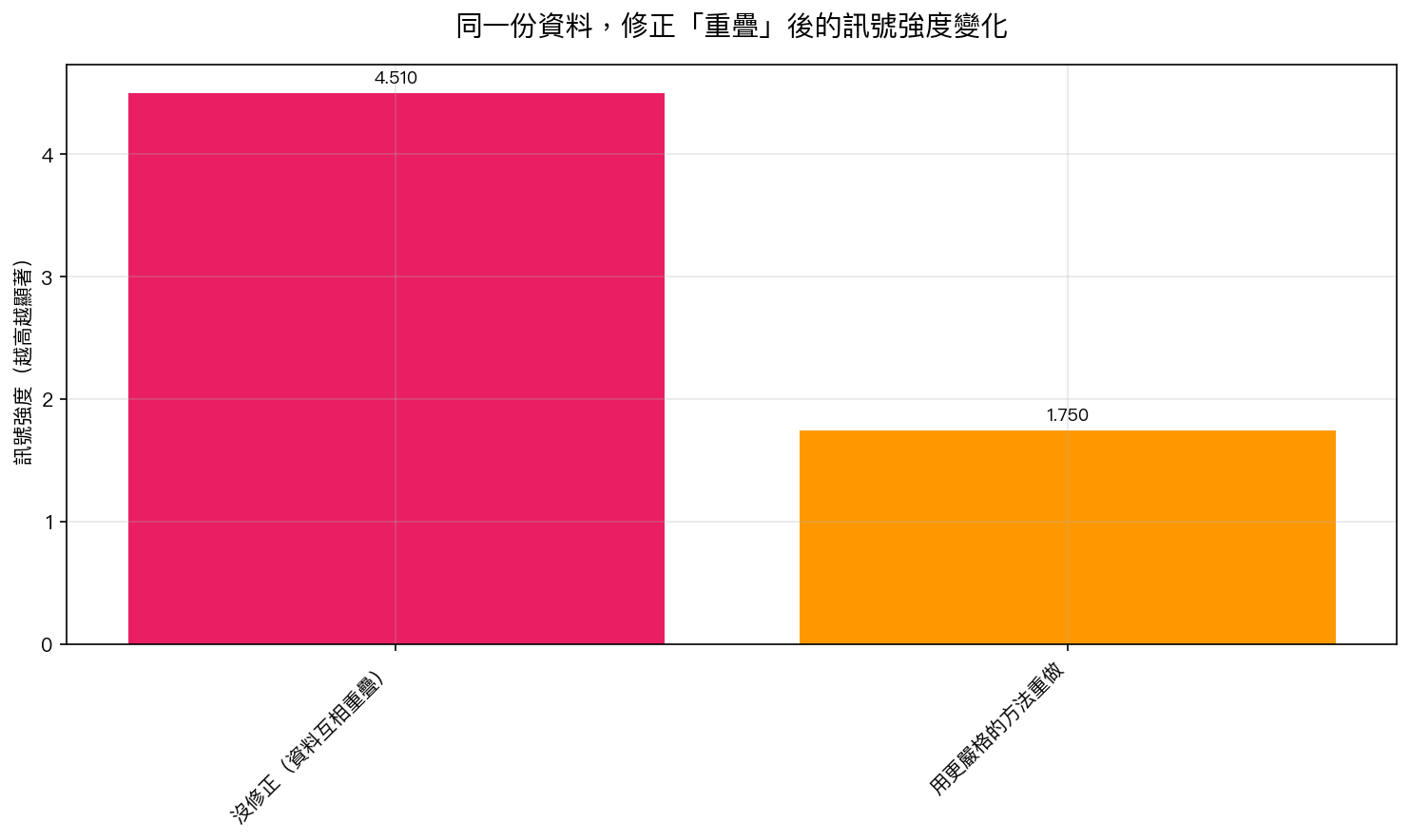
| 檢驗方法 | 訊號強度 |
|---|---|
| 原本的方法(資料彼此重疊 96%) | 看起來很強 |
| 區塊自助抽樣(不重疊、嚴格) | 訊號大幅縮水,幾乎消失 |
原本的「發現」其實大多來自資料互相重疊的幻覺 。
為什麼每個投資人都該知道這件事?
因為你看到的 絕大多數 「股價規律」、「量化因子」、「機器學習訊號」,都在某種程度上用了滾動窗口,尤其是高頻資料(日資料、分鐘資料)。
這代表:
- 學術論文 裡很多「顯著」的結果,用嚴格方法一重檢驗就消失。過去十年有一大堆論文被這樣打臉。
- 回測報告 裡的「Sharpe 3 以上」,常常是這種幻覺堆出來的。
- 機器學習訊號 特別容易中招,因為通常用很短的滾動窗口訓練。
簡單的判斷原則:
- 如果一個策略/訊號只在「連續資料」上好看,但 跨不同時間段 卻不穩定,很可能是重疊陷阱。
- 如果一個訊號的 Sharpe 比市場基準高 2 倍以上, 先懷疑有 bug ——真的那麼好賺,早就被人套利光了。
給一般投資人的三個自保原則
原則一:同一個策略要在多個獨立時段都有效才可信 。不是靠 2020-2023 好看,要 2020-2023、2010-2015、2005-2010 分三段都能站得住腳。
原則二:看到 Sharpe > 3 的策略,第一反應是懷疑,不是興奮 。問清楚:是怎麼算的?有沒有用重疊窗口?跨不同市場一樣嗎?
原則三:把你看到的 t 值、顯著性、勝率除以 2-3 當作保守估計 。大多數沒經過嚴格修正的研究結果,真實強度只有原本的 1/2 到 1/3。
一句話總結
看起來有 100 個獨立觀察值,不代表真的有 100 個獨立觀察值 。當相鄰資料互相重疊,你的統計數字就是幻覺,而這在金融研究裡是常態,不是例外。
下一步
下一篇來看另一個讓人迷信的陷阱: 明明在股票上很管用的「進階波動模型」,為什麼一搬到黃金、石油、比特幣就完全失靈 ?
本文基於研究團隊對台股三檔個股的時間序列穩健性檢驗(期間 2014-2025 年,資料來源:yfinance)。修正方法使用 Newey-West HAC 標準誤與 block bootstrap(區塊長度 24),兩層嚴格修正後,原本看似強烈的訊號全部縮水。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊