31 家公司、6 個指標、5 個假設:為什麼「看得到的特徵」無法預測財報當天的波動反應
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
31 家公司、6 個指標、5 個假設:為什麼「看得到的特徵」無法預測財報當天的波動反應
公開資料找不到規律,不代表規律不存在。K1113 實驗的結論是:市值、beta、成交量、財報頻率、歷史波動率、產業相對動能,這 6 個指標在預測財報當天波動反應差異這件事上,全部無效。5 個預先登記的假設,0 個通過。
這個實驗試圖解決什麼問題
在台灣 31 家上市公司的樣本中,我們先前發現一個現象:不同公司在財報公告日前後,股價對「預期財報波動」的反應強度差異很大。有些公司在財報前幾天波動明顯上升,有些幾乎紋風不動。
這個差異有辦法事先預測嗎?如果可以,研究者或投資人就能根據公司特徵,在財報季前就挑出哪些公司值得特別處理、哪些公司走基本模型就好。
K1113 是一個 預先登記的確認性實驗 (pre-registered confirmatory experiment)。研究設計、變數清單、成功判定標準,全部在跑資料之前就白紙黑字鎖定,不能事後修改。鎖定設計的目的是防止「試了 20 個指標,挑 2 個有效的說:看!我找到了!」這種篩選偏差(data dredging)。
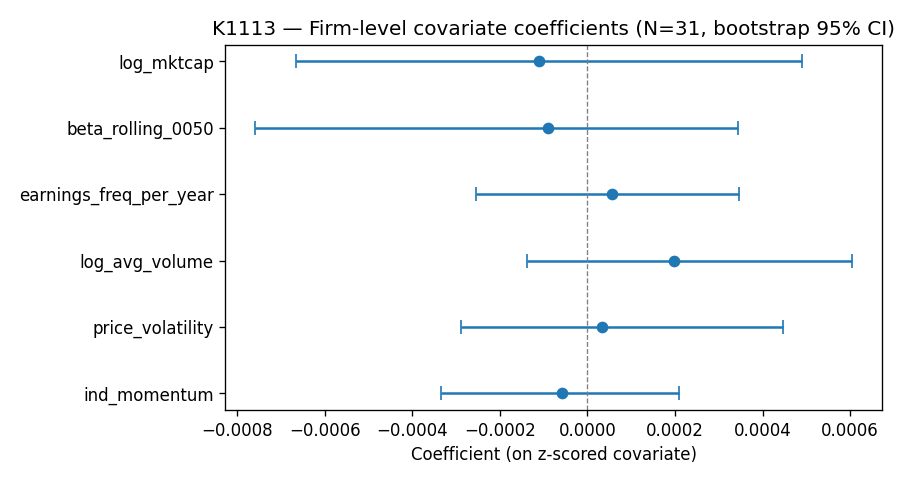
6 個指標,沒有一個站得住
| 指標 | 方向假設 | 白色穩健標準誤 p 值 | BH 校正後 p 值 | 結論 |
|---|---|---|---|---|
| 對數市值 | 負相關(大公司反應較弱) | 0.682 | 0.854 | FAIL |
| 市場 beta | 正相關(高 beta 反應較強) | 0.746 | 0.854 | FAIL |
| 年均財報次數 | 任意方向 | 0.623 | 0.854 | FAIL |
| 對數平均成交量 | 任意方向 | 0.239 | 0.854 | FAIL |
| 歷史價格波動率 | 正相關 | 0.854 | 0.854 | FAIL |
| 產業相對動能 | 任意方向 | 0.598 | 0.854 | FAIL |
BH-FDR 是 Benjamini-Hochberg 多重檢定校正,目的是控制「同時檢驗 6 個指標時,偶然冒出一個看起來顯著」的機率。校正後,最小的調整 p 值是 0.854。0.05 是一般顯著水準,0.854 距離那條線非常遠。這不是「差一點就顯著」,是完全的雜訊。
CV R² = -0.661:預測效果比瞎猜還差
在樣本內,這個 6 變數迴歸的 R² 是 0.116,看起來還有點解釋力。但這個數字是騙人的,因為它拿訓練資料自我評分。
更可靠的評估方法是 5 折交叉驗證(5-fold cross-validation):每次用 4/5 的資料訓練,拿出 1/5 的資料測試,而且訓練集和測試集的標準化參數嚴格分開計算,防止資料洩漏。
結果是:CV R² = -0.661 。
負的 R² 代表什麼?R² = 0 是「模型的預測和直接猜全部公司的平均值一樣準」,R² < 0 是「模型的預測比猜平均值還要差」。-0.661 告訴我們,這 6 個指標拼在一起,不但沒有預測力,還引入了反方向的雜訊。
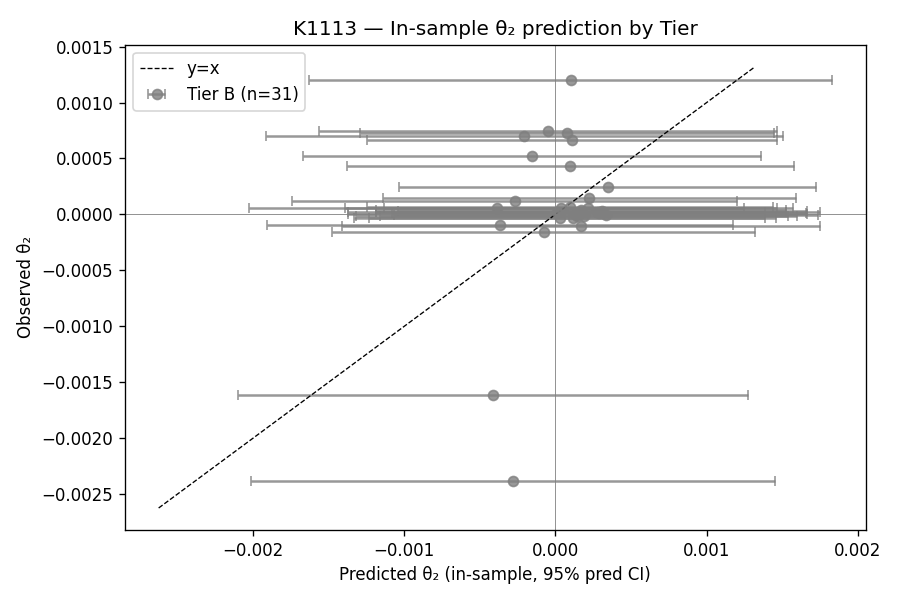
Tier A = 0:沒有任何一家公司可以被推薦使用特殊模型
實驗設計中有個實用目標:能否把 31 家公司分成三級?
- Tier A:預測顯示波動反應明確偏高,建議使用財報感知版本的 A4f 模型
- Tier B:預測不確定,用基礎版本
- Tier C:預測顯示波動反應明確偏低,建議避開財報版本
分類的方法是:用迴歸係數預測每家公司的反應強度,再計算這個預測值的完整預測區間(不只是係數不確定性,也包含殘差不確定性)。
結果:Tier A = 0 家,Tier B = 31 家,Tier C = 0 家。
全部 31 家公司都落在「不確定」的中間地帶。這個分類系統,等同於沒有分類系統。
值得一提的是:實驗過程中,Codex(GPT-5)的程式碼審查發現了一個 bug。原始程式碼在計算預測區間時,漏掉了殘差變異,只算了係數不確定性。這讓區間看起來比實際更窄,原本有 1 家公司(中鋼)被誤判為 Tier A。修正 bug 後,Tier A 歸零。 原始程式碼的錯誤讓結果看起來稍微樂觀,修正後更加悲觀。
和 K1109 對比:兩條路都走不通
上一個相關實驗 K1109 測的是產業類別(foundry、fabless、金融、航運等 8 個)能否預測反應差異。當時也全部失敗:聯合 F 檢定 F(7,20) = 1.31,p = 0.297,沒有任何顯著結果。
K1109 當時有兩個指標在連續變數迴歸中看起來邊際顯著:對數市值的白色標準誤 p = 0.027,beta 的白色標準誤 p = 0.010。K1113 把這兩個指標納入,專門設計一個乾淨的連續變數版本,結果它們的 p 值分別跳到了 0.682 和 0.746。
這說明了什麼?K1109 看到的邊際顯著,很可能是因為和產業虛擬變數的共線性。當產業類別從模型中移除,市值和 beta 的「信號」也跟著消失。那個信號本來就不屬於它們,只是搭了產業變數的便車。
| 模型 | 樣本內 R² | 交叉驗證 R² |
|---|---|---|
| K1109 產業 + 連續變數(10 個迴歸量) | 0.340 | 未報告 |
| K1109 僅連續變數(3 個迴歸量) | 0.038 | 未報告 |
| K1113 連續變數(6 個迴歸量) | 0.116 | -0.661 |
K1109 的 0.340 樣本內 R² 很好看,但它的 ANOVA p 值是 0.297,代表那個 R² 完全是過擬合出來的。K1113 的交叉驗證 R² 直接擊穿零以下,把這件事說清楚了。
這個 null result 告訴我們什麼
首先,null result 不是實驗失敗。這是一個預先登記、方法論符合規範、程式碼通過獨立審查的確認性實驗。它給出的答案很明確:用 yfinance 取得的這 6 個公開市場指標,在這 31 家公司的樣本下,對財報波動反應的差異沒有預測力。
這個結論縮小了「答案可能在哪裡」的搜索範圍。
真正的差異如果存在,比較可能藏在不容易從公開資料直接取得的地方,例如:
- 散戶委託流量的組成比例(非法人的比例越高,財報前的噪音越多)
- 公司透明度或資訊揭露品質(中文財報附錄的詳細程度、分析師預測的分歧度)
- 法人持股進出的節奏(在財報前幾週是否有明顯的異常動向)
- 可以對沖的選擇權是否存在(對沖管道會壓低波動期間的跳升)
這些資料有些在 TEJ 有、有些需要向交易所申請或爬取,不是開個 yfinance 就能取得的。
讀者可以帶走的一件事
下次你看到有報告說「某個指標可以預測 X 公司財報後的波動」,可以問以下問題:
-
樣本有多大? N=31 已經是嚴謹設計的樣本,但仍算小。如果報告的樣本是 15 家或更少,得到的「顯著」更可能是雜訊。
-
有沒有多重檢定校正? 測了 6 個指標,如果不做 BH-FDR 校正,純靠 p < 0.05 就會有高機率冒出假陽性。
-
有沒有樣本外驗證? 樣本內 R² 很容易膨脹。有效的信號需要在留出的測試集或後續時期中被複現。
K1113 三個問題都回答了。答案是:樣本 31,BH 校正後全無顯著,CV R² = -0.661。
這是 N=31 樣本下誠實的答案。它的侷限也很清楚:如果把樣本擴大到台灣全部上市公司(約 300-500 家),結果可能不同。目前這個結論只能說:在我們能乾淨地估計財報波動反應參數的 31 家公司裡,用公開市場指標找捷徑這條路走不通。
數據來源 :yfinance(市值、beta、成交量、波動率、動能)、財報公告日期(Earnings dates);實驗 K1113,台灣 31 家上市公司樣本,seed=42,bootstrap 5000 次。
相關實驗 :K1109(產業類別版本,同樣 N=31 樣本,同樣失敗)
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊