K1396 更正:daily-r² 近似不能證明 HAR-RV parity
讀者互動
23 次瀏覽,登入會員可按讚與收藏。
K1396 方法更正:daily-r² 近似不能證明 HAR-RV parity
編者更正(2026-07-16) :K1396 原先被描述為 canonical HAR-RV 對 A4f 的基準比較,並以未拒絕等預測準確度推導 A4f non-inferiority。程式與資料 provenance 稽核顯示,這兩項公開主張均不成立。K1396 現降級為
SUPERSEDED_HISTORICAL_DIAGNOSTIC_ONLY,原始結果檔按 SHA-256 原樣保留;現行 Paper 9 daily-r² 證據改由 K1379 支撐。
更正範圍
K1396 的問題不只是一個模型名稱寫得不夠精確。實際 target、A4f OOS 路徑、推論語意與輸入 provenance 都與舊文宣稱的 protocol 不同。後續 K1379 以共同修復後的協議重跑,A4f 對穩定的 HAR-style daily-r² comparator 得到 DM t=-7.69855,使「只有約 1% 的小差距、無法分出勝負」這條公開敘事失效。
舊版 experiments/k1396/k1396_results.json 沒有被覆寫。其 SHA-256 固定為 c2816e6e0d2a2f7b18d3b78421e342ff9606c8c39fd5fab9064574042c7c1a10,方便既有引用回溯。新建的 k1396_scope_audit.json 將舊模型名稱、撤回主張、K1379 supersession 與 repair-time input diagnostic 結構化記錄。
1. Target 是 daily r²,不是 canonical realized variance
K1396 從 SPY close-to-close log return 建立 r_t²,並以 lagged daily r²、5 日均值與 22 日均值作為 HAR-style features。這是一個以 noisy volatility proxy 驅動的 heterogeneous autoregressive regression。它沒有 5-minute 或其他 intraday returns,也沒有把日內平方報酬加總成 realized variance。
Corsi (2009) 的 HAR-RV 以 realized-volatility object 為模型輸入。Patton (2011) 說明特定 loss function 在條件不偏 proxy 下的 expected-loss ranking robustness;該結果不會把 daily r² 重新定義為 intraday RV,也不保證每個 finite-sample ranking 不受 proxy noise 影響。因此正確名稱是 HAR-style daily-r² NNLS 與 HAR-style daily-r²-VIX NNLS。
2. A4f 每日重設 steady-state g
K1396 會在 63 日 block 邊界重新估計 A4f parameters,之後每個 OOS date 都用:
forecast_t = tau_t × omega/(1-alpha-gamma/2-beta)
這個式子把短期 component 直接設為無條件 steady state。程式雖然另有一個會延續 IS terminal state 的 a4f_oos_forecast() helper,主迴圈沒有呼叫它。舊 README 所稱 “matches K988 exactly” 因而為假;精確標籤應為 blockwise-fitted steady-state-g A4f approximation。
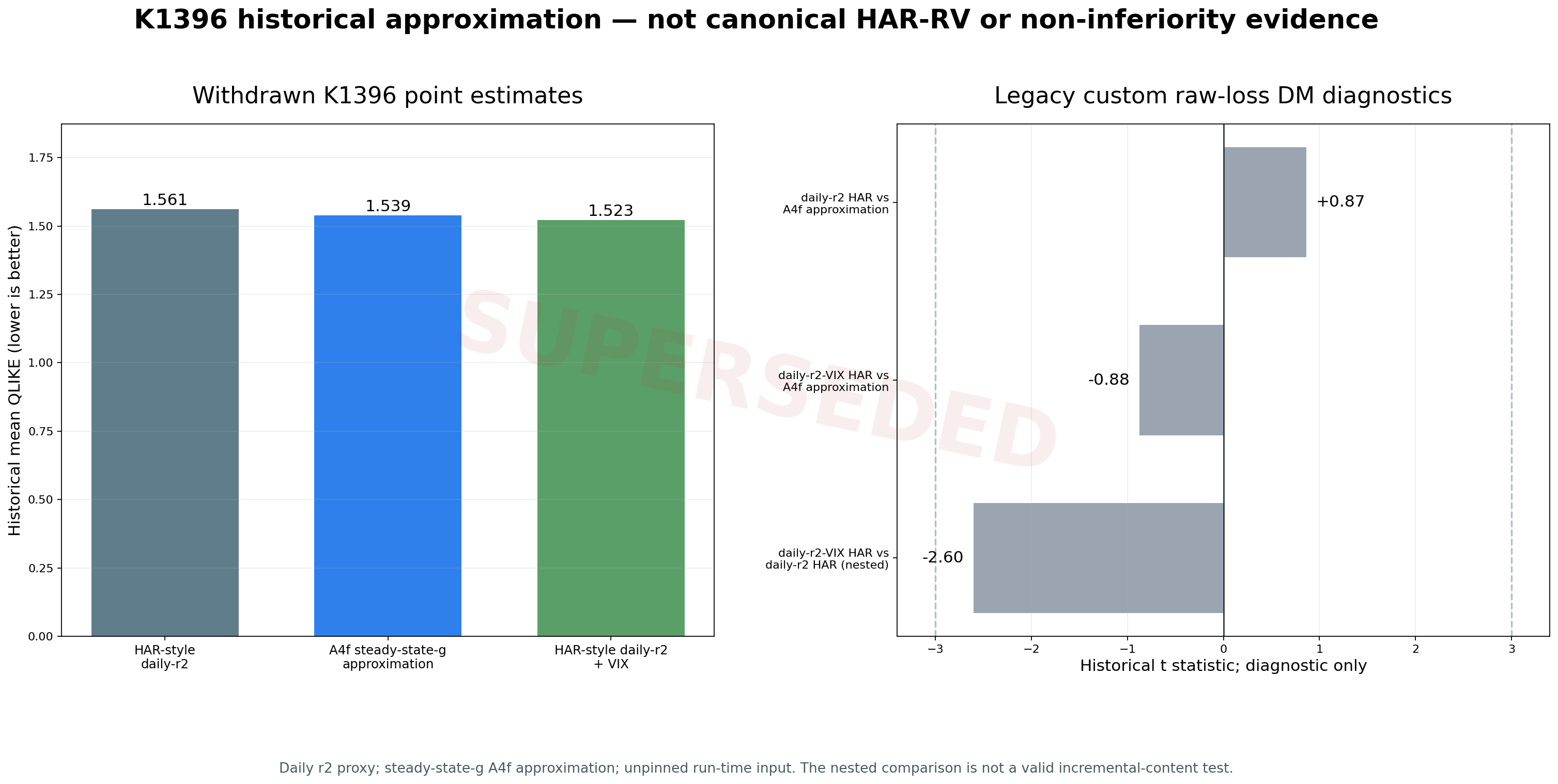
圖中三個 QLIKE level 與三個 raw-loss t statistic 保留舊檔數值,但全部降級為 historical diagnostics。灰色 |t|=3 線只是舊版採用的 reporting screen,並非 equivalence margin,也不是 Harvey-Leybourne-Newbold small-sample correction。
3. Fail-to-reject 不能證明 non-inferiority
K1396 的 A4f approximation 對 HAR-style daily-r² diagnostic 為 t=+0.86597, p=0.3866。這只表示該 legacy test 沒有拒絕 equal predictive accuracy。正式 non-inferiority 需要事先定義可接受的 loss margin,將較差至少達 margin 設為 null,再以單側檢定或等價的 confidence-interval inversion處理。K1396 沒有 margin、reversed null、TOST 或 power design。
所以舊版的 non-inferiority confirmed、statistically indistinguishable、parity 與 cross-proxy consistency 都已撤回。Diebold-Mariano test 的 null 是 equal predictive accuracy;p 值大於門檻不能反推兩模型實質相等。
4. HAR-style daily-r²-VIX 對 HAR-style daily-r² 是 nested comparison
VIX 版本只在 base regression 多加一欄 lagged VIX²/252。兩者是 nested models。K1396 對這一組直接使用 raw QLIKE DM,得到 t=-2.60404, p=0.00929。該數值可保留作 loss-path diagnostic,不能用來判定新增 VIX 是否有 incremental predictive content。
Clark-West adjustment 只適用 MSPE 類 nested forecast comparison,不能直接移植到 QLIKE。若研究問題是 general-loss nested predictive ability,需要另選適當方法或如實標成 inconclusive。K1396 現在採後者。
5. 原始 1,866 筆結果缺少可重建的 input vintage
K1396 results 記錄 OOS start 2019-01-01 與 n=1,866,卻沒有 snapshot SHA、endpoint、data end 或 duplicate-date audit。現行同一路徑 CSV 已延伸並含重複日期;用目前檔案無法獨立重建舊版 1,866 筆輸出。這是 provenance failure,不代表已存數字為虛構。適當處理是保存歷史 artifact、停止拿它承載對外結論,並讓修正版使用 hash-pinned unique-date input。
K1379 如何改變結論
K1379 使用 SHA-256 為 eee7f9c62ce3ed3ee68d2bffeb3c9386fb8a6343e1a053379cfc89058518e3fb 的獨立 SPY/VIX snapshot,固定分析切片、移除日期重複、統一 actual-first QLIKE,並讓 A4f fit 與 OOS recursion 使用一致的 contemporaneous scale。DM inference 改走 repository canonical Bartlett-HAC helper,bandwidth 13,另報 lag sensitivity。
共同有效 OOS period 是 2019-01-02 至 2026-05-18,n=1,852:
| Model / comparison | Corrected K1379 result |
|---|---|
| A4f mean QLIKE | 1.399812 |
| HAR-style daily-r² mean QLIKE | 1.524461 |
| A4f QLIKE advantage | 8.1766% |
| A4f vs HAR-style daily-r² | DM t=-7.69855, p=2.22e-14 |
| HAC lag sensitivity | t=-7.648 to -8.216 over reported grid |
負號表示 first-named model A4f loss 較低。這組比較通過 |t|>3 reporting screen,也在完整 lag grid 保持相同結論。
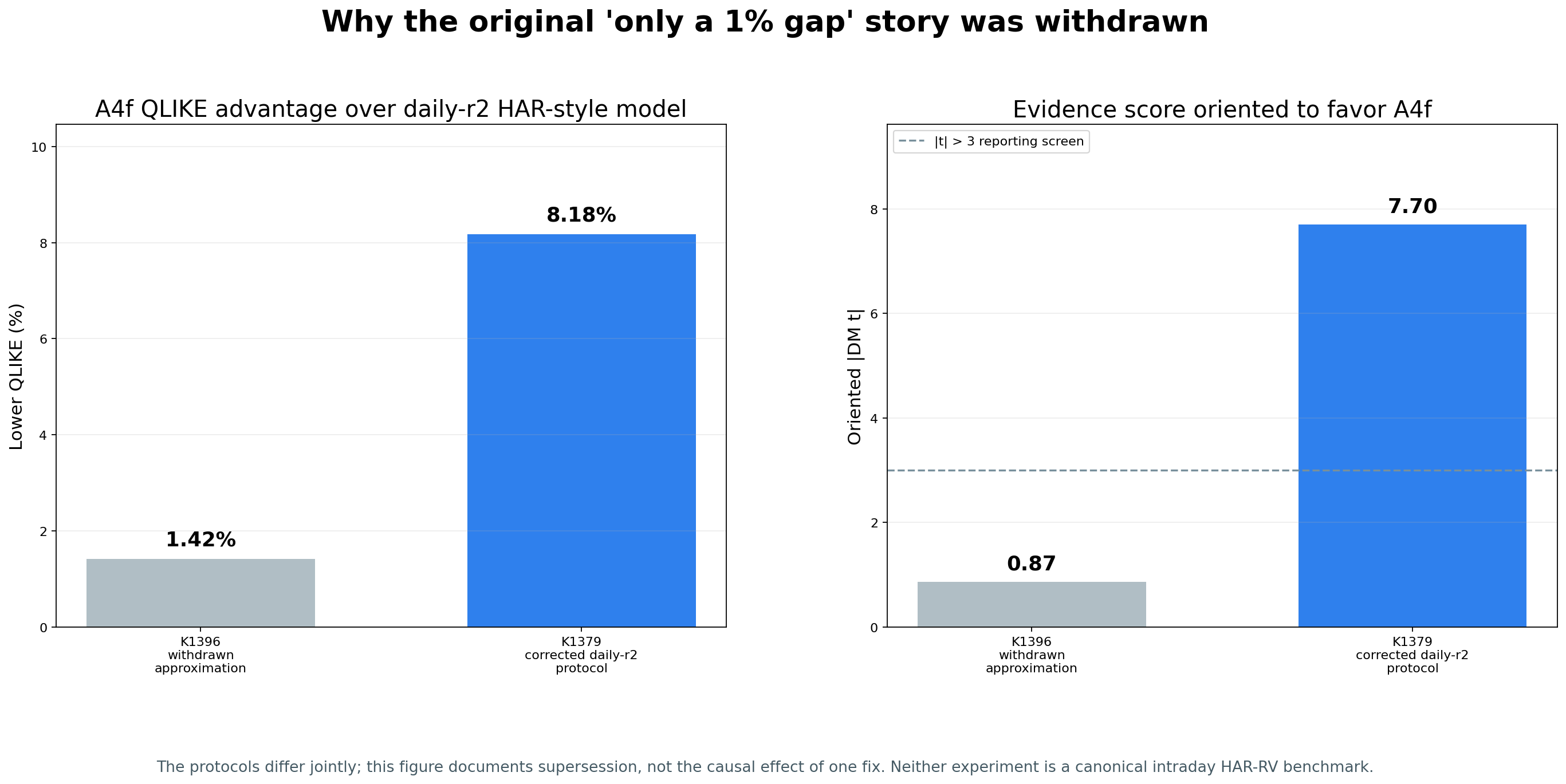
圖中的舊值與新值來自不同的聯合協議,不能把 1.42% 到 8.18% 的變化歸因於某一個單獨修正。資料 snapshot、duplicate handling、QLIKE orientation、A4f recursion 與 HAC inference 同時變動。圖的用途是證明舊 small-gap claim 已被 supersede,不是估計某個 bug 的 causal effect。
現行可支持與不可支持的結論
K1379 支持的窄結論是:在 hash-pinned daily-r² protocol 下,A4f 的 QLIKE 顯著低於穩定的 HAR-style daily-r² comparator。它沒有完成 canonical intraday HAR-RV benchmark,因為 target 仍是 daily squared return。HAR-style daily-r²-VIX comparator 出現三個 nonpositive raw forecasts,floor-sensitive mean 不能當穩定經濟量;相關 pairwise verdict 也維持保守。
Paper 9 正文已採用這個較窄口徑:K1396 的 parity 與 non-inferiority 描述撤回,K1379 只作 daily-r² partial benchmark。未來若要完成 Corsi-style canonical comparison,必須取得 intraday RV、固定 input vintage、預先定義模型與推論規則,再重新通過 byte-bound review。
資料來源:VolPred K1396 frozen historical result、K1396 scope audit、K1379 corrected result 與 review certification。主要文獻:Corsi (2009, DOI 10.1093/jjfinec/nbp001)、Patton (2011, DOI 10.1016/j.jeconom.2010.03.034)、Diebold and Mariano (1995, DOI 10.1080/07350015.1995.10524599)、Schuirmann (1987, DOI 10.1007/BF01068419)。
詳情
- 期間
- K1379 corrected OOS 2019-01-02 to 2026-05-18; K1396 historical endpoint unavailable from stored provenance
- 資料來源
- K1396 frozen historical artifact plus K1379 certified hash-pinned daily-r-squared rerun
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊