風險模型愈花俏愈準嗎?這次市場給了相反答案
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
2026-06-13 修訂(Codex 24h 來源審查) 本文保留核心結論:FHS 在 1% 與 5% 的 pinball loss 點估計最低,直接分位數模型沒有證明自己值得升級。但原文「5% 水準五個模型全都沒完整過關」容易被讀成所有 5% 覆蓋率檢定都失敗。正確讀法是:若沿用本實驗的嚴格 Trinity screen(含 Basel-style 250-day traffic-light screen),五個模型都未完整過關;若只看 Kupiec + Christoffersen 覆蓋率,Normal、FHS、CAViaR、QuantHAR 在 5% 水準是過關的。
做風險預測的人,很容易有一個直覺:模型愈新、愈複雜,應該愈準。
這次我們把 5 種 SPY 尾部風險模型丟到同一段 2019-01-02 到 2026-04-02 的真實市場裡,直接看誰比較接近市場。樣本一共 1,823 個交易日,包含疫情暴跌、升息熊市,還有 2023 之後的低波動反彈。
比較結果很不給新模型面子。
最低的尾部損失分數,1% 和 5% 兩個水準都由 FHS 拿下;CAViaR 和 QuantHAR 都沒贏。真正在 1% 水準通過三道基本檢查的,只有 Student-t 和 FHS 。到了 5% 水準,結論要拆開看:覆蓋率檢定多數模型可以過,但若再加上本實驗沿用的 Basel-style 250-day screen,五個模型都沒有完整過關。
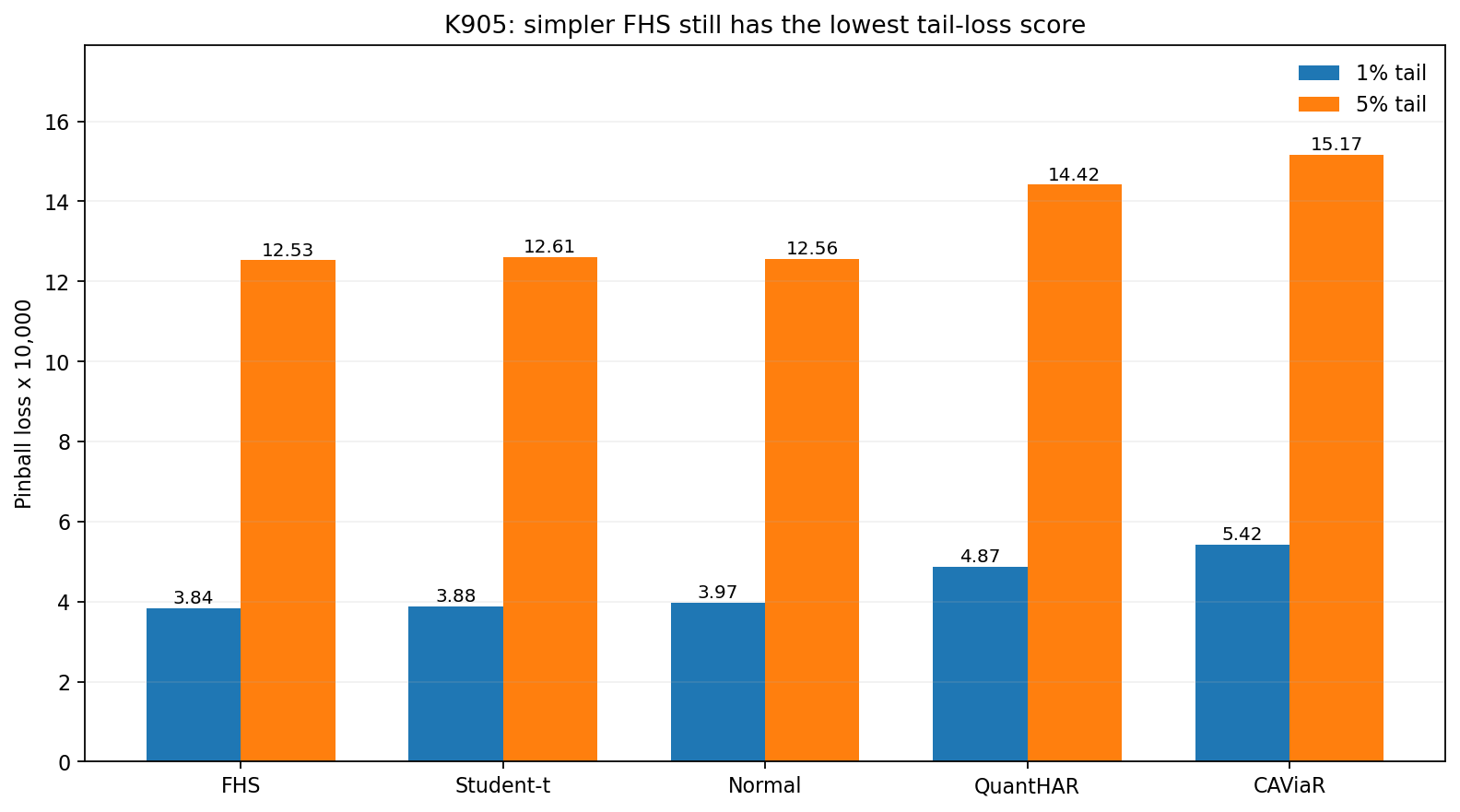
第一張圖最值得看。藍色是 1% 尾端,橘色是 5% 尾端。柱子愈低愈好。
FHS 兩個水準都排第一。Student-t 緊跟在後,但差距不大。CAViaR 和 QuantHAR 的點估計排名落後。也就是說,直接去預測分位數,這次沒有比「先抓波動,再用歷史尾巴補上去」更厲害;但這裡講的是點估計排名,不是正式顯著勝出。
這結果的重點其實很冷: 複雜度沒有自動換成準度。
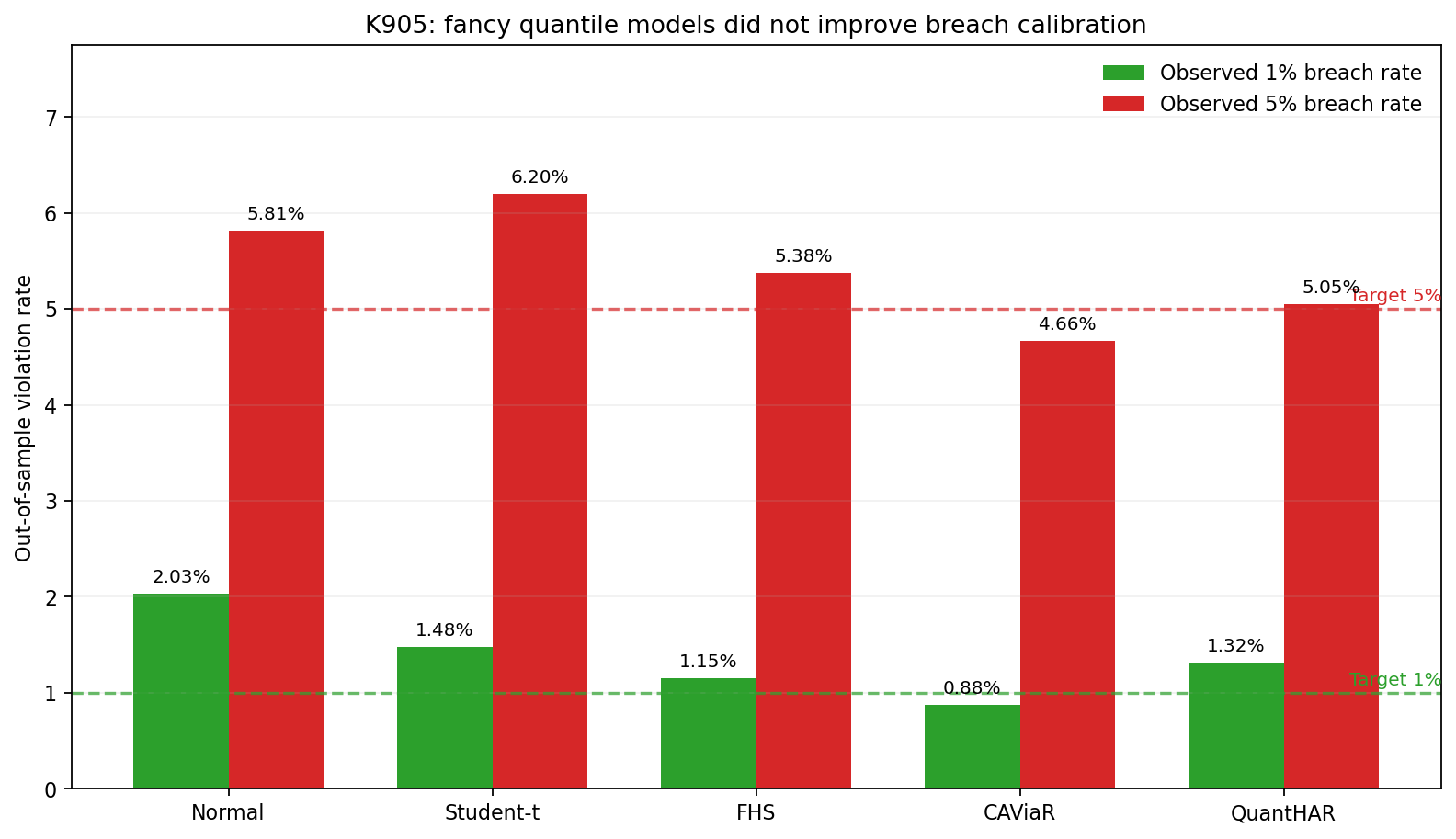
第二張圖看的是「出事頻率有沒有報對」。綠線是理論上 1% 風險該出現的位置,紅線是 5%。
這裡可以看到三件事:
- Normal 太樂觀。1% 真實踩線率是
2.03%,等於你以為百日一見,市場其實五十天左右就來一次。 - CAViaR 在 1% 水準反而太保守,踩線率只有
0.88%,但事件會擠在一起,沒把風險節奏抓好。 - QuantHAR 看起來接近目標值,可是一碰到連續壓力期,穩定度還是不夠。
5% 水準最容易誤讀。只看「平均踩線率有沒有接近 5%、踩線事件有沒有明顯群聚」這兩件事,Normal、FHS、CAViaR、QuantHAR 都可以過關;Student-t 在 Kupiec 覆蓋率檢定上沒過。可是本實驗還把最近 250 天的 Basel-style screen 一起放進來,這個 screen 對 5% VaR 很嚴,結果五個模型都沒有完整過關。
所以這個實驗給投資人最實用的提醒,不在「快去用 FHS」這個層次。它要說的是更基本的事:
不要因為模型名字更新,就以為風險控制一定更好。
這次在 SPY 身上,老派但紮實的 FHS 依然守住點估計第一。Student-t 至少在 1% 水準過關。至於 CAViaR 和 QuantHAR,概念很漂亮,這輪外樣本還沒證明自己值得升級。
如果你的目標只是把尾部風險估得比較準,這份結果其實很節制:先把簡單方法做到位,可能比急著換新模型更重要。
本文基於實驗 k905(腳本:experiments/k905/k905_quantile_vol_forecast.py,結果:experiments/k905/k905_quantile_vol_forecast_results.json)。資料來源:yfinance 的 SPY 日資料,估計期間 2005-01-01 至 2026-04-02,評估期間 2019-01-02 至 2026-04-02,樣本 1,823 個交易日。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊