風險模型最怕的不是猜不準平均,而是你以為安全、其實根本沒罩住
風險模型最怕的不是猜不準平均,而是你以為安全、其實根本沒罩住
很多人看風險模型,第一眼只看「平均有多準」。
但真正會害人虧大錢的,通常不是平均值,而是另一件事:
模型說它已經把最壞情況包進去了,結果真正出事時,根本沒包住。
這份 SPY 實驗測的,就是這個問題。
它不是單純比誰的平均預測比較漂亮,而是直接比較五種模型誰更能回答一句投資人真正會在意的話:
「如果接下來真的很糟,我的風險大概會糟到哪裡?」
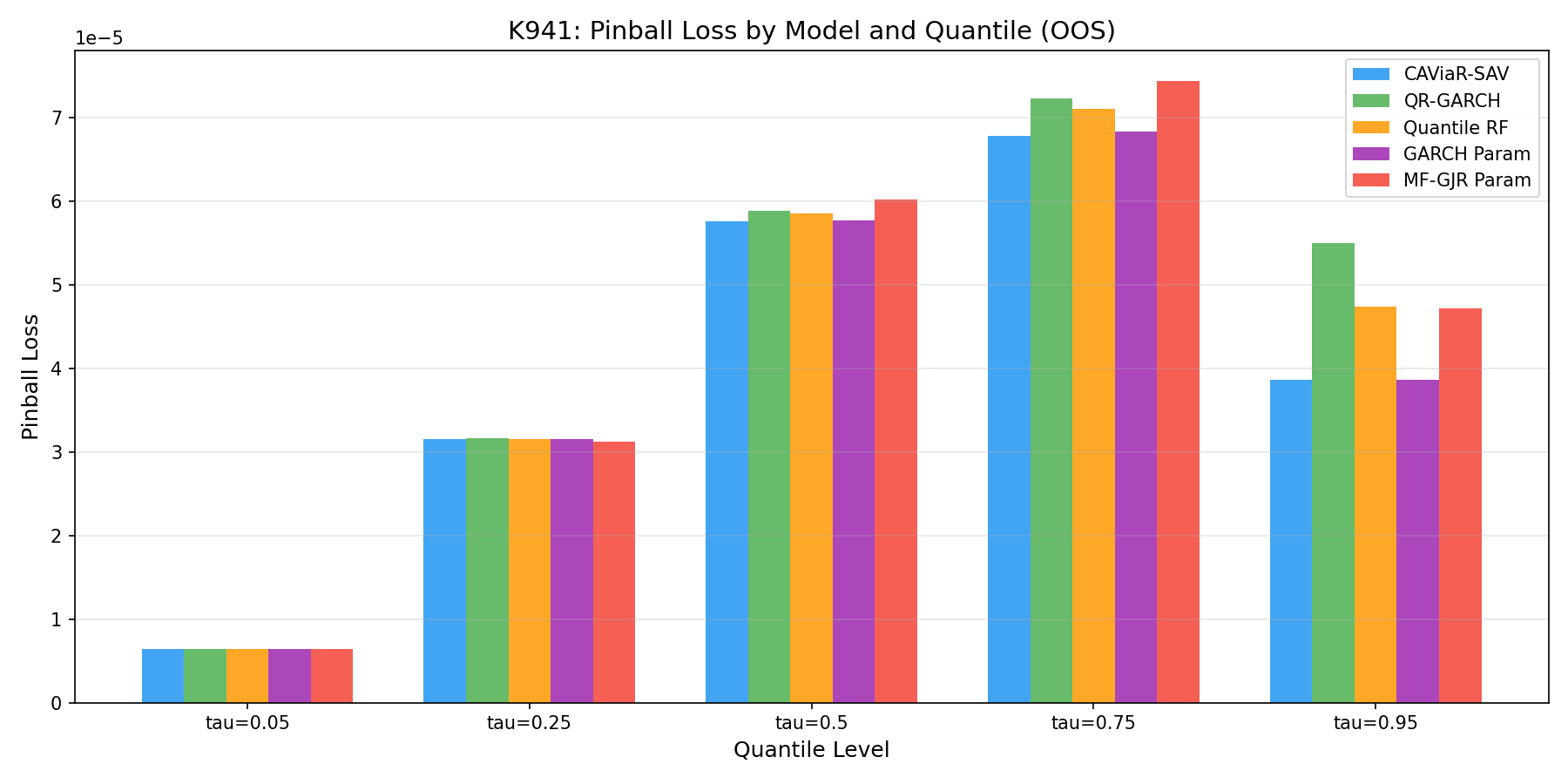
先講最重要的結論
這次測試的五種方法裡,表現最穩的是 CAViaR-SAV。
它不靠先假設市場報酬長什麼分配,而是直接去追「風險區間本身」怎麼動。
如果只看整體排名,大致是這樣:
| 排名 | 模型 | 表現 |
|---|---|---|
| 1 | CAViaR-SAV | 最佳 |
| 2 | 傳統參數法 | 幾乎追平 |
| 3 | Quantile Random Forest | 再差一點 |
| 4 | 另一種進階參數法 | 再後面 |
| 5 | 線性分位數版本 | 最差 |
真正有意思的不是第一名是誰,而是第二個發現:
傳統參數法居然跟第一名咬得非常近。
這代表對 SPY 這種成熟市場來說,老方法並沒有很多人想像中那麼落後。
什麼叫「有沒有包住」
你可以把它想成颱風警報。
如果氣象局說:
「明天 90% 的可能情況都在這個範圍裡。」
那真正重要的不是這句話聽起來多專業,而是隔天發生的結果,到底是不是大部分真的落在這個範圍裡。
這份實驗就拿這個角度去看五種模型。
目標很簡單:
如果模型說自己能包住 90% 的情況,那實際上就應該接近 90%。
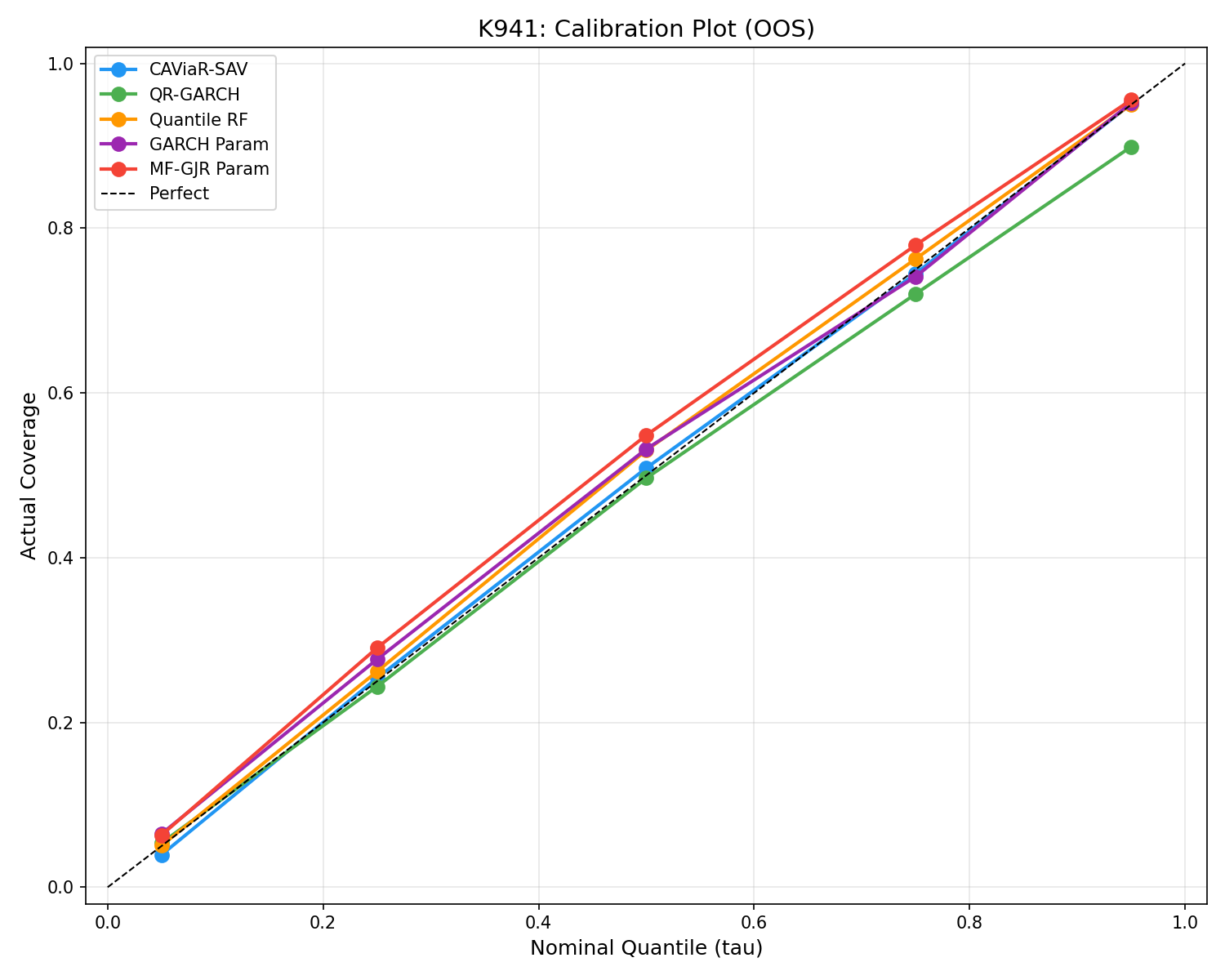
結果最關鍵的幾個數字是:
| 模型 | 實際包住比例 |
|---|---|
| CAViaR-SAV | 91.2% |
| Quantile RF | 90.0% |
| 進階參數法 | 89.3% |
| 傳統參數法 | 88.7% |
| 線性分位數版本 | 84.6% |
這裡最值得注意的,不是第一名,而是最後一名。
那個最線性的分位數版本,名義上也在做風險區間,但它實際只包住 84.6%,離應有的 90% 差了一大截。
白話講就是:
它說你大部分時候會安全,結果真正不安全的次數,比它承諾的還多。
這對風險管理是很糟的錯誤。因為這種錯不是「有點不準」,而是會直接讓你低估自己暴露在外面的尾部風險。
這篇實驗最反直覺的地方
很多人會以為,越新的方法應該越厲害。
機器學習、更多特徵、更多結構,看起來都像升級。
但這份實驗最反直覺的地方剛好是:
最花俏的方法沒有贏很大,最老派的方法反而守得很好。
傳統參數法雖然不是第一名,但幾乎追平最佳模型。這說明一件事:
對 SPY 這種資料很長、結構相對穩定的市場,很多尾部風險其實還是能被老派方法抓到大半。
真正拉開差距的,不是誰的數學寫得更複雜,而是誰對「最壞情況」的校準比較誠實。
投資人最該帶走的觀念
這份結果很適合提醒一件常被忽略的事:
風險模型不只要看預測漂不漂亮,還要看它有沒有把危險真的罩住。
平均值預測得再準,如果最糟情況一直漏接,你在壓力大時還是會受傷。
所以看風險模型時,至少要分開想兩件事:
- 它平常預測準不準
- 它在你最需要它的時候,有沒有真的守住
這份實驗的答案很清楚:
CAViaR-SAV在這兩件事上最平衡- 傳統參數法沒有輸很多,甚至意外地接近
- 那個最線性的分位數版本,最大問題不是表面排名,而是它把你以為安全的區間畫得太樂觀
對實務上有什麼用
如果你真的要拿模型來做風險控制,而不是拿來寫報告,這篇的提醒很直接:
- 不要只看平均誤差,還要看區間到底有沒有包住。
- 老方法不一定落伍,尤其在成熟市場裡,穩定和誠實常常比花俏更重要。
- 如果某個模型把風險區間畫得太漂亮,反而要更小心,因為它可能只是把真正的尾巴藏起來。
對一般投資人來說,這其實也是一個很實用的判斷原則:
真正好的風險模型,不是讓你看起來比較安心,而是讓你在真的有事時沒那麼容易被打到措手不及。
資料來源
本文基於本平台一份 SPY 條件分位數風險預測實驗。資料來源:yfinance,期間 2006-01-04 至 2025-12-30,樣本外驗證期間 2016-01-04 至 2025-12-30,共 2,513 個交易日。比較方法涵蓋直接追蹤風險區間的模型、傳統參數法、隨機森林分位數法與其他參數式變體;評估重點為整體預測表現與 90% 風險區間是否真的包住實際結果。