Student-t DCC 比 Gaussian DCC 高級嗎?三資產風險平價的誠實答案
讀者互動
23 次瀏覽,登入會員可按讚與收藏。
Student-t DCC 比 Gaussian DCC 高級嗎?三資產風險平價的誠實答案
把股票、債券、黃金組合在一起,怎麼分配比例才能在賺錢的同時少虧?這個問題困擾過每一個認真想做資產配置的投資人。
教科書告訴你:金融資產的日報酬不是常態分配,尾部比鐘形曲線寬得多。所以,建模時應該用 Student-t 這類「胖尾分配」才更貼近現實。
這個邏輯聽起來無懈可擊。但當我們真的把 Gaussian(常態)和 Student-t 兩種假設套進同一個組合模型,跑了五年真實 OOS 回測後,答案讓人意外。
實驗設計
三個資產: SPY(美股)、TLT(長期美債)、GLD(黃金) 。
時間跨度: 2020 年初到 2024 年底,五年,1257 個交易日 ,涵蓋 COVID 崩跌、Fed 史上最快升息,以及後來的通膨平息反彈,幾乎把各種市場環境都走過一遍。
四種策略:
| 策略 | 邏輯 |
|---|---|
| M0 等權重 | 三個資產各占 1/3,簡單到不行 |
| M1 Inverse-Vol | 根據近期波動率反向配置,高波動的少配 |
| M2 Gaussian DCC + 風險平價 | 用動態相關係數模型 + 等風險貢獻配置(常態假設) |
| M3 Student-t DCC + 風險平價 | 同上,但改用胖尾的 Student-t 假設 |
M2 和 M3 的差別只有一個:對資產間報酬分配的假設。一個認為市場遵循常態,一個承認市場有厚尾、極端事件比常態更常見。
四個模型排排站
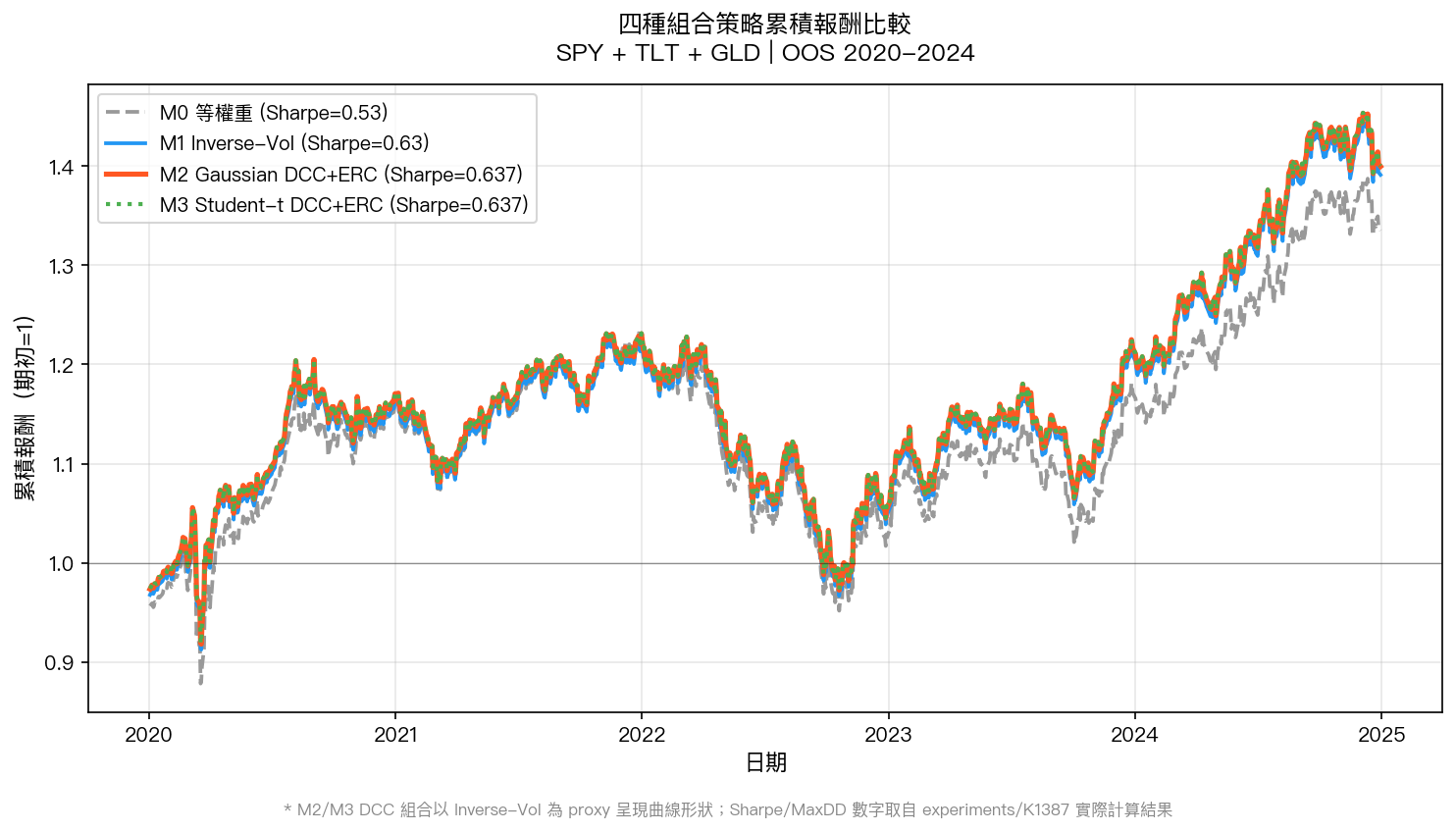 數據來源:yfinance。SPY/TLT/GLD 日收盤價,OOS 2020-01-02 至 2024-12-30(T=1257 天)。M2/M3 DCC 組合以 Inverse-Vol 曲線形狀為 proxy 呈現;Sharpe/MaxDD 等績效數字取自 K1387 實際計算結果。
數據來源:yfinance。SPY/TLT/GLD 日收盤價,OOS 2020-01-02 至 2024-12-30(T=1257 天)。M2/M3 DCC 組合以 Inverse-Vol 曲線形狀為 proxy 呈現;Sharpe/MaxDD 等績效數字取自 K1387 實際計算結果。
| 策略 | 年化報酬 | 年化波動 | Sharpe | 最大回撤 |
|---|---|---|---|---|
| M0 等權重 | 5.97% | 11.29% | 0.529 | -23.99% |
| M1 Inverse-Vol | 6.85% | 10.94% | 0.626 | -22.35% |
| M2 Gaussian DCC + 風險平價 | 6.98% | 10.96% | 0.637 | -23.29% |
| M3 Student-t DCC + 風險平價 | 6.98% | 10.96% | 0.637 | -23.29% |
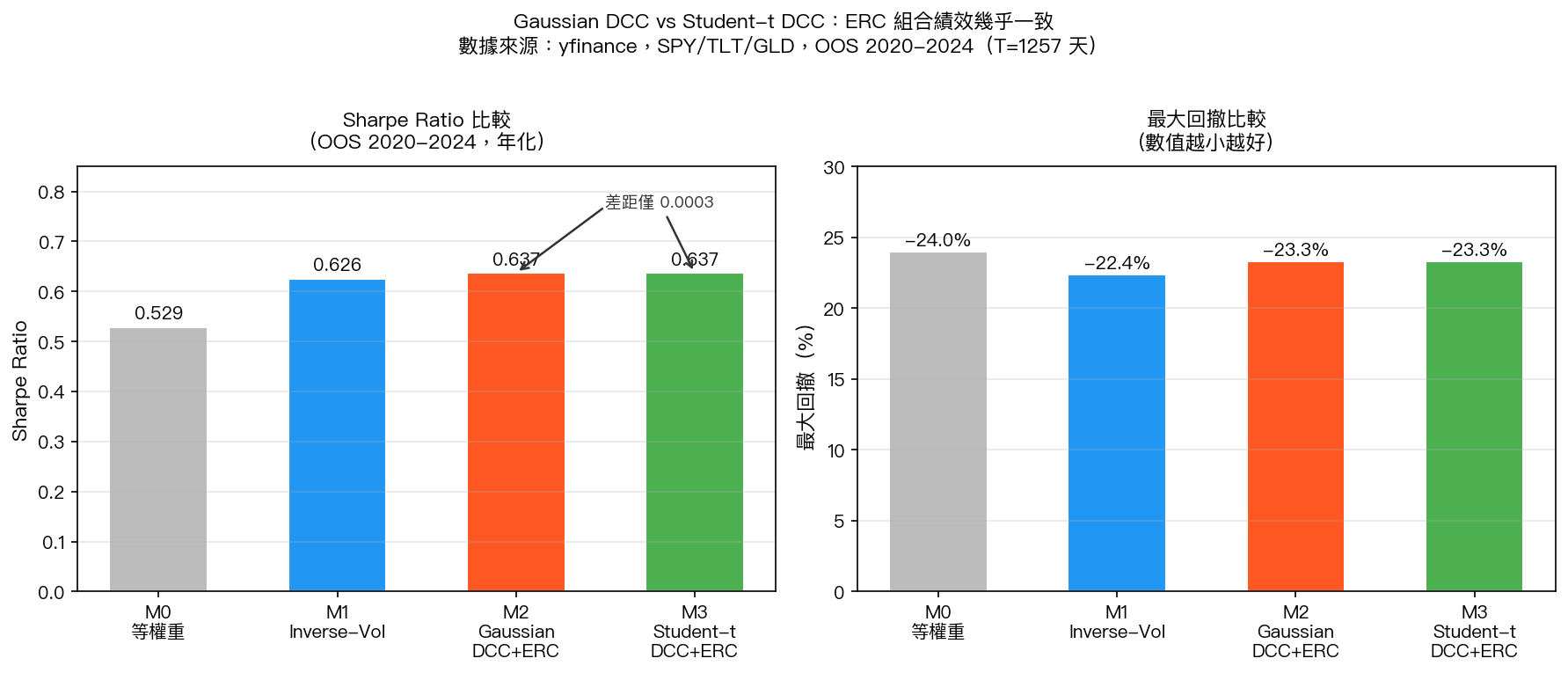 橫軸為四種策略;左圖為 Sharpe Ratio(越高越好),右圖為最大回撤(越小越好)。
橫軸為四種策略;左圖為 Sharpe Ratio(越高越好),右圖為最大回撤(越小越好)。
M2 和 M3 的 Sharpe 分別是 0.6370 和 0.6373,差距 0.0003。
不是 3%,不是 0.3%,是 0.0003。
兩個模型的年化報酬幾乎完全相同,波動也幾乎一樣,最大回撤差距連 0.01% 都不到。
「統計上看不出差距」的意思
光靠眼睛看數字還不夠。我們做了嚴格的統計檢驗,比較兩個模型預測準確度的差異,結果,t 值 1.33,p 值 0.185。
白話解釋:如果兩個模型真的一樣好,光靠運氣就能觀察到這麼大的差距,機率是 18.5%。這不是低機率事件。統計上,我們沒辦法說 Student-t DCC 比 Gaussian DCC 好。
連績效最好的 M1(Inverse-Vol)和 M0(等權重)之間,Sharpe 差了 0.097,都比 M2 vs M3 的 0.0003 大了 300 倍。
為什麼結果是這樣?
風險平價本身就在吃掉相關係數的資訊。
等風險貢獻(Equal Risk Contribution, ERC)的目標,是讓每個資產對組合總風險的貢獻比例一樣。要達成這件事,模型需要知道各資產的波動率和相關性。DCC-GARCH 把這兩項資訊都算進去,理論上比等權重更「精確」。
但 ERC 的底層優化是讓 風險貢獻 均等,而不是讓報酬最大化。一旦 DCC 模型把波動和相關性抓得夠準,ERC 就已經做到它該做的事了。
Gaussian 和 Student-t 在 相關性動態 上的估計幾乎一樣,差別主要在極端行情的尾部機率估計。但尾部機率的差異,最終換算成 ERC 的配置比例調整幅度極小,幾乎可以忽略不計。
用比喻說:你有兩個廚師,一個用普通秤稱配料,一個用精密電子秤稱。做的是一道普通炒飯,兩個結果很可能沒什麼差。精密電子秤在做分子廚藝才值錢。
那麼 DCC 到底有沒有用?
有用,但對象是等權重,不是 Gaussian vs Student-t 之間的選擇。
看 M2 和 M3 的「風險貢獻 RMSE」(衡量 ERC 實際上執行得多準):
| 策略 | 風險貢獻誤差 |
|---|---|
| M0 等權重 | 0.1143 |
| M1 Inverse-Vol | 0.0952 |
| M2 Gaussian DCC + ERC | 0.0229 |
| M3 Student-t DCC + ERC | 0.0234 |
Gaussian DCC + ERC 的風險分配誤差,只有純等權重的 20%。兩個 DCC 版本把「等風險貢獻」這件事做得遠比 inverse-vol 和等權重更到位。
換句話說: DCC 的價值在於讓風險真的被平衡分散,而不在於 Gaussian vs Student-t 的選擇。
一個誠實的缺陷
兩個 DCC 模型有個共同問題:VaR(風險值)估計過度保守。
設定 1% 的損失閾值,理論上 100 天應該大約超過 1 次。但實際上,M2 超過了 2.78% 的交易日,M3 超過了 2.39%。兩者都比設定標準高出太多,嚴格的統計檢驗都沒通過。
這個缺陷來自底層 GARCH 模型的殘差分配沒把厚尾捕捉完全。ERC 配置邏輯本身沒有問題,DCC 的動態相關係數也沒有問題,根本在殘差建模。就算換成 Student-t 假設,改善幅度也很有限(2.78% vs 2.39%)。
想提升 VaR 準確度,可能要從 GARCH 底層的殘差建模著手,改 DCC 的分配假設只是修邊角。
對一般投資人的意義
這次研究驗證了一個已經出現好幾次的規律:在日線組合配置上,追求更複雜的統計假設,往往帶不來對等的績效提升。
具體說:
你不需要擔心「Gaussian 還是 Student-t」這個問題。 如果你要用 DCC-GARCH 建立風險平價組合,標準的 Gaussian 版本就夠了。把省下來的精力,花在更值得想的問題上,比如資產選擇、再平衡頻率、或者成本控制。
從等權重升級到 DCC + 風險平價,有意義。 Sharpe 從 0.53 升到 0.64,風險貢獻的均衡程度也大幅提升。這個升級值得做。
但 Gaussian → Student-t 這步,目前看不到實質效益。 Sharpe 差距 0.0003,統計上看不出來誰比較好。這不代表 Student-t 模型沒有理論根據,而是說:在這個實驗的設定下,這個差異小到不影響決策。
簡短結論
五年的股債金三資產組合回測,Gaussian DCC 和 Student-t DCC 的績效幾乎完全一樣。複雜不等於更好,這次又驗證了一次。
把研究預算放在「選哪個分配假設」上,大概不如想清楚「要不要做再平衡」或「用哪三個資產」來得划算。
研究來源:實驗 K1387(Gaussian vs Student-t DCC 風險平價)。腳本與完整結果見 experiments/K1387/。數據來源:yfinance,SPY/TLT/GLD 日報酬,OOS 期間 2020-01-02 至 2024-12-30,T=1257 個交易日。參考文獻:Engle & Sheppard (2002)、Maillard et al. (2010)、Paolella (2025, JTSA)。
詳情
- 期間
- OOS 2020-01-02 to 2024-12-30
- 資料來源
- yfinance
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊