計算風險值的兩種非參數做法:FHS 與滾動 CF 的等價之爭
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
計算風險值的兩種非參數做法:FHS 與滾動 CF 的等價之爭
一句話結論
當我們把「資產明天最壞會虧多少」這個問題交給電腦計算,業界其實有好幾種做法在彼此競爭。本研究在三個美國 ETF(SPY、QQQ、GLD)上把四種做法各跑了 1,827 個交易日的實測,結果發現: 只要願意捨棄「報酬呈鐘形分配」的假設、改用過去 252 個交易日的真實尾端,無論是教科書級的「過濾歷史模擬法」(FHS)還是同樣非參數的「滾動 Cornish–Fisher 修正」,兩者的表現都通過了所有六項風險檢驗(共 12/12,100%);而傳統假設常態的做法在三檔 ETF 上幾乎是全軍覆沒 。換句話說,做風險管理的人若還在用常態假設算 VaR,是時候升級了。
為什麼這個問題值得普通投資人關心
風險值(Value-at-Risk,簡稱 VaR)是一個投資組合「正常情況下,明天的虧損不會超過多少」的數字。譬如 1% VaR = 3% 的意思是:理論上每 100 個交易日只會有 1 天的虧損超過 3%。聽起來像是基金經理人或巴塞爾協定才會關心的東西,但其實它與每一個用槓桿、做選擇權、做期貨、或單純想知道「最壞我會虧多少」的散戶都直接相關。
問題在於, 算 VaR 用什麼方法,會直接影響估出來的數字 ,而不同方法的「準度」差很多。最常見的誤用是把報酬假設成常態分佈(鐘形曲線),但市場報酬的尾端遠比常態厚,也就是「黑天鵝」其實沒那麼罕見。一旦尾端被低估,VaR 就會被低估,於是真正的暴跌頻率會超過模型預期。本研究就是要量化這個落差,並比較兩個替代方案: FHS(Filtered Historical Simulation,過濾歷史模擬) 與 CF-Rolling(滾動 Cornish–Fisher 修正) 。
研究設計:2 × 4 因子設計,三檔 ETF
本研究採用 2 × 4 的全因子設計:
- 波動率模型 2 種 :GJR-GARCH(捕捉「下跌時波動跳高」的不對稱性)vs A4f(一個結合 VIX 為外生變數的乘法型 GARCH-X 模型)
- VaR 估計方法 4 種 :
- Normal :假設標準化殘差是常態分佈(最傳統做法)
- Student-t(df=8) :假設殘差是肥尾的 t 分配
- CF-Rolling :用過去 252 個交易日標準化殘差的偏度與峰度做 Cornish–Fisher 修正(K1036 已證實 6/6 通過 Trinity 檢驗)
- FHS :直接從過去 252 個交易日標準化殘差取經驗分位數,不假設任何分配(Barone-Adesi & Giannopoulos, 1999)
樣本期間 2005-01-01 至 2026-04-10, OOS 樣本外從 2019-01-01 起算 ,每檔 ETF 都有 1,827 個 OOS 交易日。重新估計頻率為 63 天,估計視窗 2,000 天,固定隨機種子 42。每個「資產 × 模型 × 方法 × α 水準」組合都跑了 Kupiec 失敗率檢驗、Christoffersen 條件覆蓋檢驗、巴塞爾紅綠燈,以及 ES(期望損失)的 Acerbi–Szekely 檢驗,只有三個檢驗全部通過才算「Trinity PASS」。
結果一:常態假設根本不及格
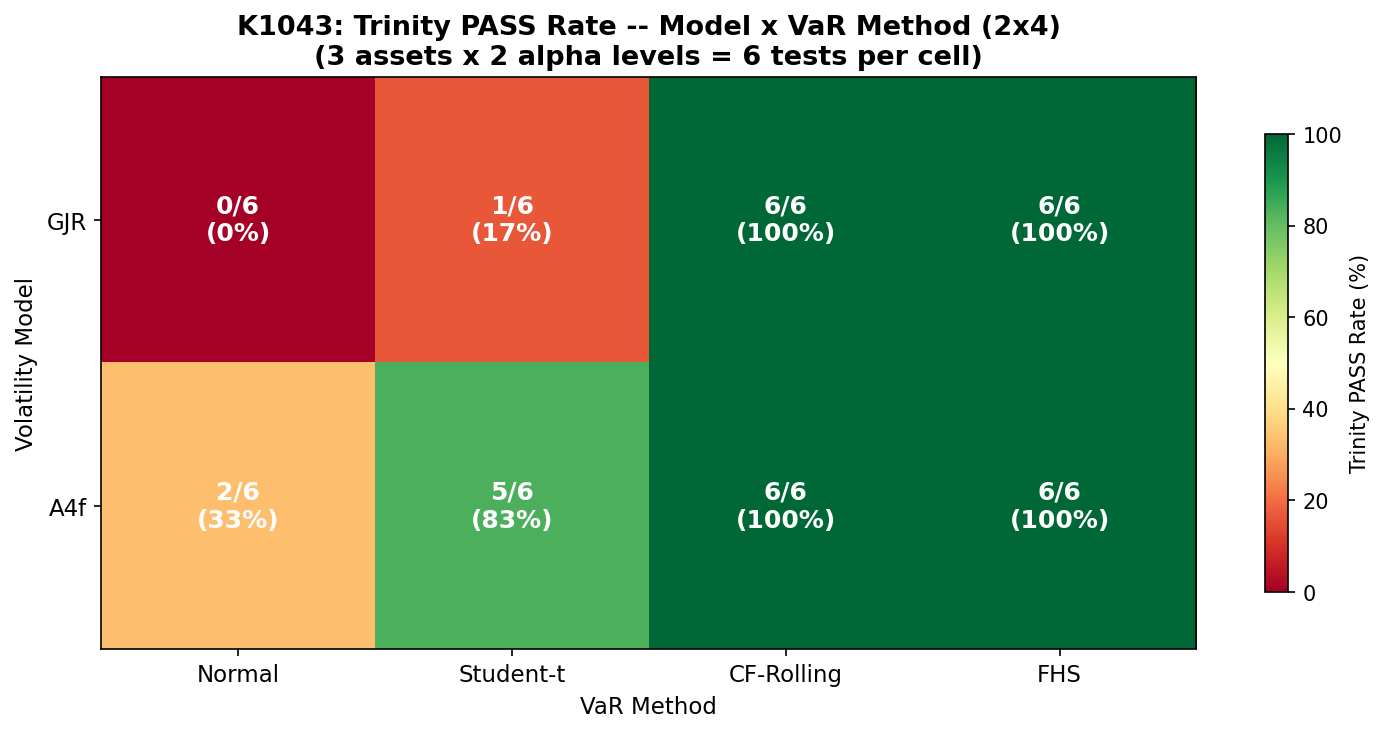
先看最重要的 2 × 4 表(Trinity 通過率,每格分母 6 = 3 檔 ETF × 2 個 α 水準):
| 模型 \ 方法 | Normal | Student-t | CF-Rolling | FHS |
|---|---|---|---|---|
| GJR | 0/6(0%) | 1/6(17%) | 6/6(100%) | 6/6(100%) |
| A4f | 2/6(33%) | 5/6(83%) | 6/6(100%) | 6/6(100%) |
如果把模型平均掉、只看 VaR 方法的表現:
- Normal:2/12(16.7%) ——12 次測試只通過 2 次,被巴塞爾紅綠燈大量打成「紅燈」
- Student-t(df=8):6/12(50.0%)
- CF-Rolling:12/12(100.0%)
- FHS:12/12(100.0%)
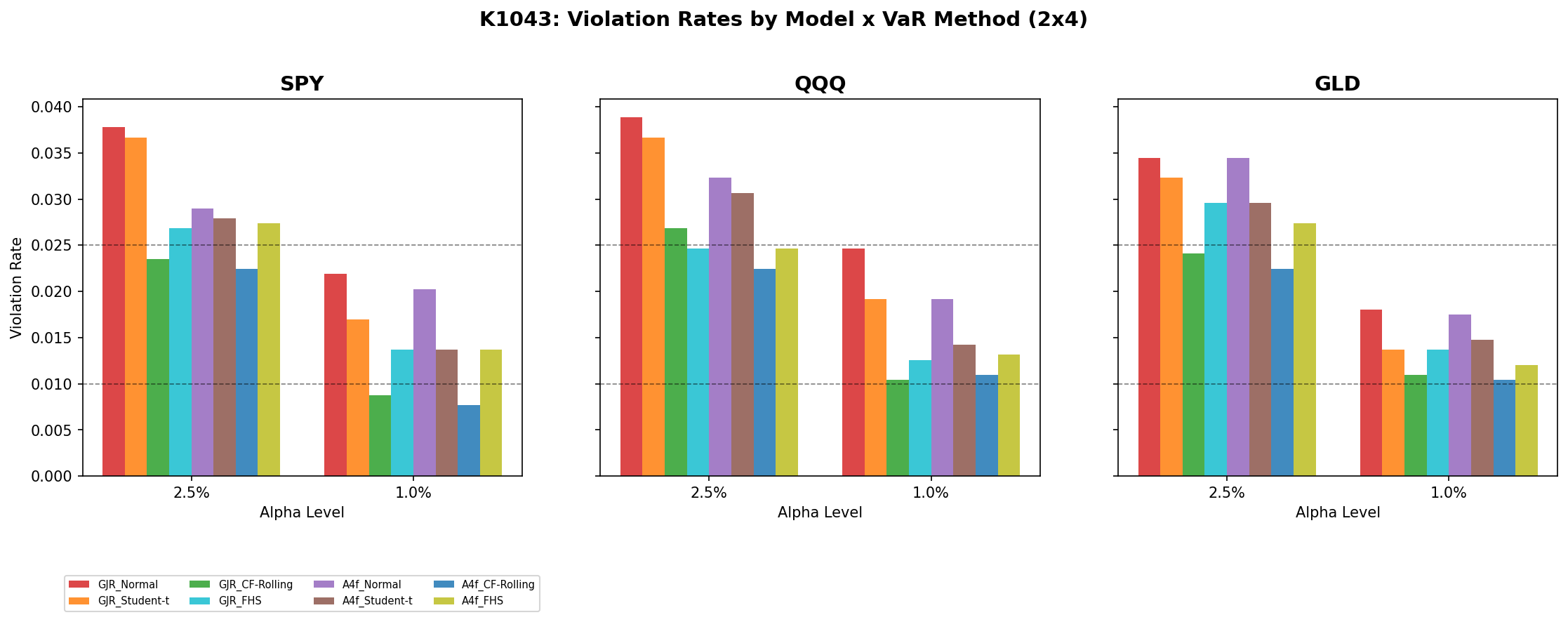
具體看數字會更清楚。以 SPY 在 1% VaR 為例:
- GJR + Normal :實際違反率 2.19%,是預期 1% 的 2.2 倍 ,Kupiec 重抽樣比較直接拒絕
- GJR + Student-t :實際違反率 1.70%,仍是預期 1.7 倍,達顯著水準
- GJR + CF-Rolling :實際違反率 0.88%,與預期 1% 幾乎一致
- GJR + FHS :實際違反率 1.37%,雖然偏高但通過
QQQ 在 1% VaR 的常態做法更慘,實際違反率 2.46%,是預期的近 2.5 倍,Kupiec 重抽樣比較直接打成顯著違反。GLD 也類似。
這個結果在實務上的意義很直接 :你若用常態假設算 1% VaR,那個你以為「每 100 天才會發生 1 次」的暴跌,其實大約每 50 天就會發生一次。對於用槓桿的投資人或要做風險預算的基金經理人,這個誤差會直接轉化為部位過大、爆倉風險被低估的後果。
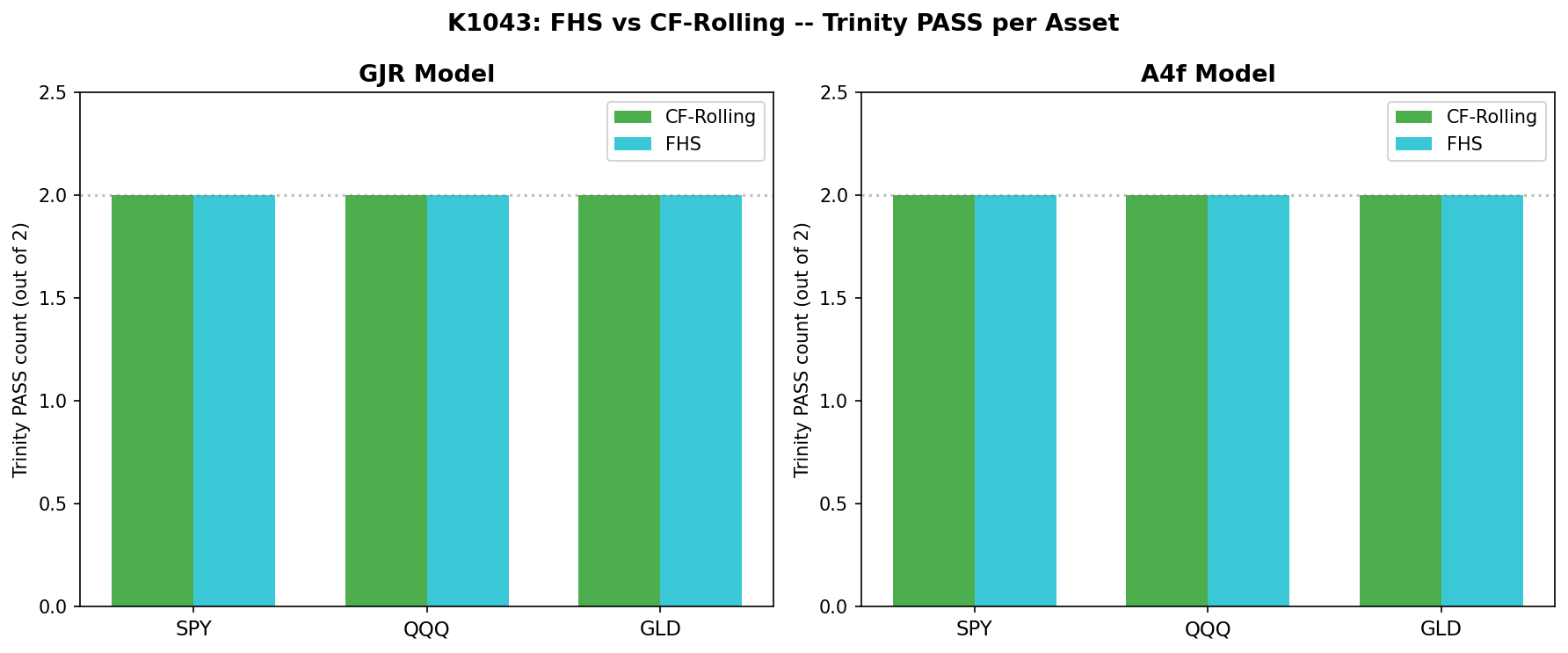
結果二:兩個非參數方法統計上不可區分
研究設計的另一個重點是 FHS 與 CF-Rolling 的兩兩比較 。它們表面看起來很像(都用 252 天的滾動視窗、都不假設分配),但運作機制不同:FHS 直接拿經驗分位數,CF-Rolling 則用過去視窗的偏度與峰度去修正常態分位數。 理論上 CF-Rolling 比較「平滑」,FHS 對極端值比較敏感 ——本研究想看這個機制差異會不會在實證上顯現。
結果是 12 組比較檢定(3 檔 ETF × 2 個模型 × 2 個 α 水準), 沒有任何一組達到顯著水準 。最大的統計強度出現在 QQQ × GJR × 1% 的組合(統計量約 1.65),仍未達常規嚴格統計檢驗門檻。其他多數組合的統計強度都在 0.5 以下,比較得到的差異與隨機波動無法區分。
換句話說, 這兩個非參數做法在實務上是可以互換的 。哪個比較好不是學術問題、而是實作便利度問題:
- FHS 比較簡單:只要排序、取分位數,連矩量都不用算。
- CF-Rolling 多算偏度與峰度,但有一個額外好處,你可以 逐天看到偏度與峰度怎麼變動 ,當市場進入「峰度暴漲」的階段(例如 2020 年 3 月、2022 年 9 月),CF-Rolling 給的數值會自然張大。FHS 也會張大,但解釋上不那麼透明。
對於想做風控報告、跟投資人解釋「為什麼今天 VaR 突然變大」的人,CF-Rolling 在透明度上佔優勢;對於只想要一個 robust VaR 數字的人,FHS 是更輕量的選擇。
結果三:模型選擇是次要的,分位方法才是主要的
A4f 模型在 2 × 4 表中整體表現比 GJR 好(19/24 = 79.2% vs 13/24 = 54.2%),這個 +25 個百分點的差距值得記下來。但仔細拆開看, A4f 帶來的改善幾乎都集中在參數方法上 :
- Normal:GJR 0/6 → A4f 2/6(A4f 有改善但仍不及格)
- Student-t:GJR 1/6 → A4f 5/6(A4f 大幅改善)
- CF-Rolling:兩者都 6/6(A4f 沒額外貢獻)
- FHS:兩者都 6/6(A4f 沒額外貢獻)
這是一個 重要且稍微違反直覺的發現 。傳統思維會認為「更好的波動率模型 + 更好的 VaR 方法 = 加乘效果」,但本研究顯示一旦 VaR 方法已經是非參數的,再去升級波動率模型對 Trinity PASS 率的邊際貢獻幾乎為零。 真正卡住風險估計品質的瓶頸不是「波動率動了多少」,而是「尾端形狀對不對」 ——而尾端形狀只有非參數方法(FHS 或 CF-Rolling)能正確捕捉。
這對實務有兩個 takeaway:
- 不要為了升級 GARCH 規格而升級 。如果你已經用 FHS 或 CF-Rolling,在 GJR 之上加 VIX 外生變數的邊際效益是零。把資源放在其他地方(例如資料品質、refit 頻率、跨資產相關性)會更划算。
- 如果你受限只能用參數法(Normal 或 Student-t),那 VIX 增強的 A4f 的確有幫助 ——尤其在 Student-t 上從 17% 拉到 83%。這對於某些受監理限制只能用標準分配假設的機構是個 viable workaround。
結果四:ES(期望損失)全部通過——VaR 才是關卡
在 48 個 ES(Acerbi–Szekely)檢驗中, 所有 48 組全部通過 。這意味著「一旦突破 VaR 之後,平均虧損是多少」這個問題,所有方法(包括失敗的 Normal)都沒問題。
換個角度說: ES 不是這個資料集的瓶頸,VaR 的違反頻率才是 。失敗的方法不是把虧損規模估錯,而是低估了暴跌的「機率」。一旦低估了暴跌頻率,部位就會放太大,當真的撞上才會發現「平均虧損」其實不算太離譜,但「虧損發生次數」遠超預期。
圖表
實務應用建議
對普通投資人與風險管理人員,本研究的 takeaways 可以濃縮成三句話:
- 如果你算 VaR 還在用常態假設,請立刻換成 FHS 或 CF-Rolling 。差異不是學院討論,而是 100 個交易日真實違反率 1% vs 2.2% 的差別。
- FHS 與 CF-Rolling 二選一都可以 ,本研究 12 次比較檢定都顯示沒有顯著差異。選擇條件取決於:(a) 你有多需要解釋偏度峰度給利害關係人聽(→ CF-Rolling)、(b) 你想要實作多簡單(→ FHS)。
- 不要把資源花在升級波動率模型 。一旦尾端用非參數法處理,從 GJR 升級到 A4f(或更複雜的模型)對 Trinity PASS 率沒有邊際貢獻。
本研究的限制
- 三檔 ETF(SPY/QQQ/GLD)皆為高流動性美股市場代表 ,結論不直接外推到流動性較差的個股、新興市場、或加密貨幣。
- OOS 期間 2019-01-02 起涵蓋 2020 年 3 月與 2022 年熊市 ,但個別 ETF 仍可能有 idiosyncratic regime(例如 GLD 的避險屬性)。
- 252 天滾動視窗 是行業慣例選擇,K1036 已驗證為較佳長度。視窗縮短到 126 天或拉長到 504 天的 sensitivity 由後續 K 處理。
- df=8 是 Student-t 的固定值 ,未做 df 的 estimation。完整 GHST 或 EGB2 等更彈性的參數族未在此比較範圍內。
資料來源
- 原始資料:yfinance(SPY、QQQ、GLD 日報酬,2005-01-01 至 2026-04-10)
- 樣本期間 5,349 個交易日,每檔 ETF OOS 樣本 1,827 個交易日(2019-01-02 起算)
- 完整實驗腳本與結果 JSON:
experiments/k1043/ - 相關前期實驗:K1036(A4f + CF-Rolling 6/6 通過 Trinity 檢驗)、K905(FHS 在前一輪比較中勝過 CAViaR / QuantHAR)
主要參考文獻
- Barone-Adesi, G., & Giannopoulos, K. (1999). VaR without correlations for portfolios of derivative securities. Journal of Futures Markets, 19(5), 583–602.
- Cornish, E. A., & Fisher, R. A. (1938). Moments and cumulants in the specification of distributions. Revue de l'Institut International de Statistique, 5, 307–320.
- Kupiec, P. H. (1995). Techniques for verifying the accuracy of risk measurement models. Journal of Derivatives, 3, 73–84.
- Christoffersen, P. F. (1998). Evaluating interval forecasts. International Economic Review, 39(4), 841–862.
- Acerbi, C., & Szekely, B. (2014). Back-testing expected shortfall. Risk.
- Engle, R. F., Ghysels, E., & Sohn, B. (2013). Stock market volatility and macroeconomic fundamentals. Review of Economics and Statistics, 95(3), 776–797.
本文為自主研究系統實驗 K1043 的讀者版報告,數據與結論可在實驗目錄完整復現。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊