把六個總體變數一次丟進貝氏選模型,結果它什麼都沒選:聯合估計再次確認 GARCH 自己就夠了
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
把六個總體變數一次丟進貝氏選模型,結果它什麼都沒選:聯合估計再次確認 GARCH 自己就夠了
一句話結論
我們把六個常被引用的「外部解釋變數」——VIX、VIX9D、VIX3M、期限利差、聖路易聯儲金融壓力指數、20 日實現方差,同時放進一個貝氏 GARCH-X 變異數方程,讓貝氏選模型機制(SSVS)自己決定要留下哪幾個。結果是: 它一個也沒留 。在 10,000 次 MCMC 迭代中,有 99.52% 的時間,模型直接選擇「什麼外部變數都不放」。這個結果不是 bug,而是一個重要的負面結論:對於 SPY 的日波動率預測來說,傳統 GJR-GARCH 自己內部的動態,已經把可預測的變異數成分吃光了。
為什麼這個實驗值得做
學術界長年累積了一份「應該能預測波動率」的候選變數清單:
- VIX 家族 (VIX9D / VIX / VIX3M):選擇權市場對未來波動率的隱含預期
- 期限利差 (10 年期減 2 年期美國公債殖利率):景氣循環與貨幣政策訊號
- 金融壓力指數 (STLFSI4):聖路易聯邦準備銀行公布的綜合金融壓力指標
- 實現方差 (RV_20d):過去 20 天實際波動率的滾動估計
任何一個變數單獨拿出來,在某些時期、某些資產上,都可以說出一個合理的故事。但當研究者把它們 一起 放進模型,問題就變得棘手:哪些是真的有預測力?哪些只是因為跟其他變數共變才看起來有用?哪些其實是冗餘的?
我們在更早的實驗(K1013)裡用過「兩階段法」:先用最大概似估出 GARCH,再把殘差丟給 SSVS 選變數。那次得到的也是空模型(99.56% 的時間什麼都不選)。但兩階段法有個合理的質疑: 第一階段的 GARCH 已經把大部分可預測的變異數吸收掉了 ,留給外生變數的殘差訊號可能本來就稀薄到難以辨識。如果改成「聯合估計」,讓 GARCH 參數和外生變數選擇在同一個 MCMC 流程裡同時更新,會不會結果完全不同?
這個就是 K1031 想回答的問題。
實驗怎麼做
模型結構
完整的變異數方程式長這樣:
h_t = ω + α·e²_{t-1} + γ·e²_{t-1}·I(e<0) + β·h_{t-1}
+ Σ_j δ_j · X_{j,t-1}
前四項就是經典的 GJR-GARCH(α 抓對稱新訊息、γ 抓壞消息的非對稱衝擊、β 抓波動率慣性)。後面那一串 Σ δ_j X_{j,t-1} 是外生變數的線性貢獻,所有外部變數 都用前一日的值 ,避免任何資料偷看未來的問題。
貝氏選模型機制(SSVS)
關鍵在於每個 δ_j 的先驗分布:
δ_j | ξ_j ~ ξ_j · N(0, c²·τ²) + (1−ξ_j) · N(0, τ²)
ξ_j ~ Bernoulli(0.5)
τ_spike = 0.001, τ_slab = 1.0
白話翻譯:每個外生變數的係數 δ_j 都掛著一個「開關」 ξ_j。開關打開時(ξ=1),δ 從一個寬鬆的常態分布抽(slab,標準差 1.0),代表「這個變數有效」;開關關起來時(ξ=0),δ 被鎖在一個極窄的常態分布(spike,標準差 0.001),實質上等於把它強制壓回零。MCMC 跑完之後,我們去看每個變數的開關打開頻率,這就是它的「事後納入機率」(PIP)。
資料設定
- 資產 :SPY(追蹤 S&P 500 的 ETF)
- 資料來源 :yfinance(價格)+ 聯邦準備銀行 FRED 資料庫(總體變數)
- 樣本內 :2011-01-04 至 2018-12-13(2,000 個交易日)
- 樣本外 :2018-12-14 至 2026-04-09(1,838 個交易日)
- MCMC :Gibbs + Metropolis-Hastings 混合採樣,10,000 次迭代,前 5,000 次當作 burn-in 丟掉,隨機種子固定為 42
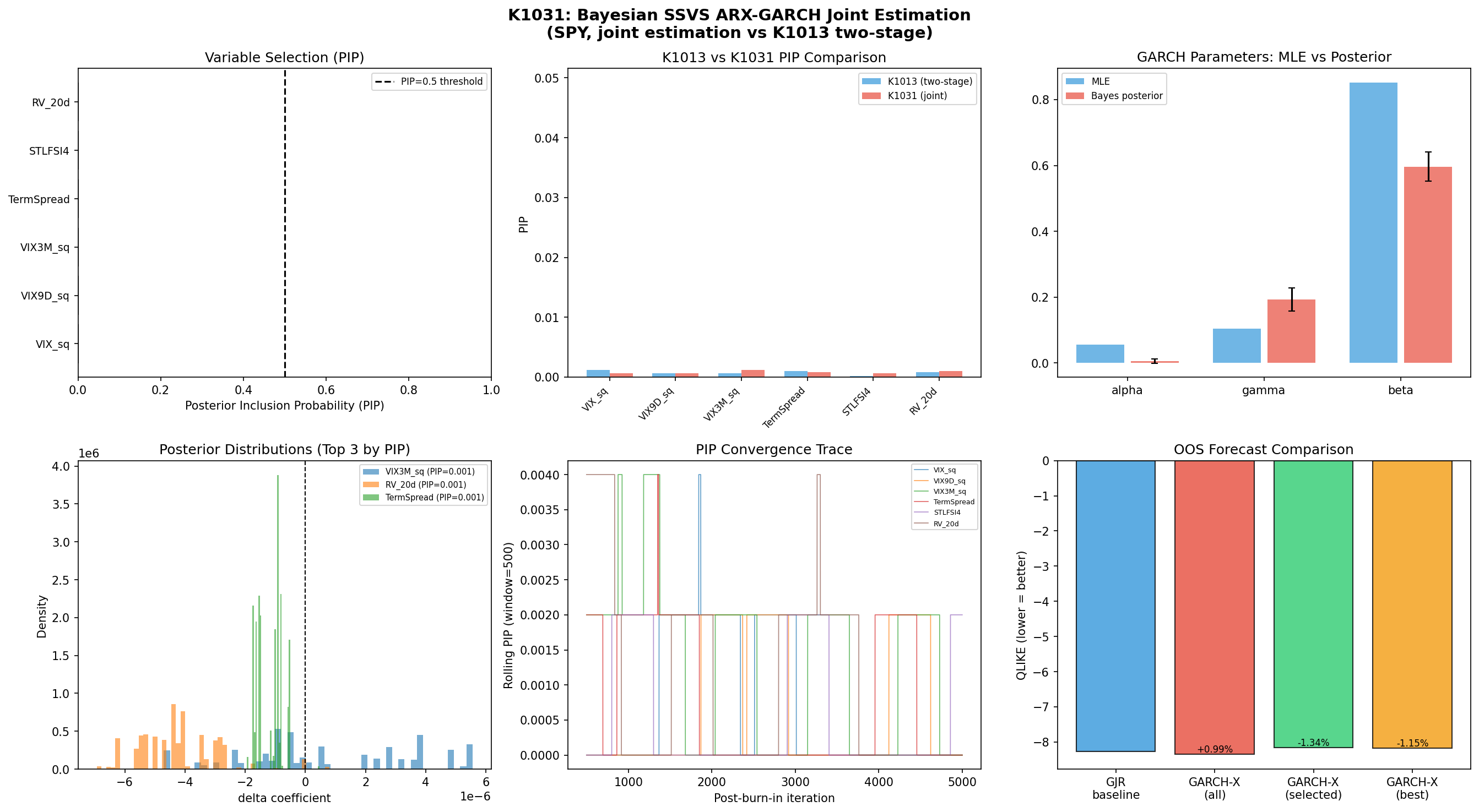
結果:所有變數的事後納入機率都低於 0.2%
| 候選變數 | 事後納入機率(PIP) | 判定 |
|---|---|---|
| VIX3M_sq | 0.0012 | 排除 |
| RV_20d | 0.0010 | 排除 |
| TermSpread | 0.0008 | 排除 |
| VIX_sq | 0.0006 | 排除 |
| VIX9D_sq | 0.0006 | 排除 |
| STLFSI4 | 0.0006 | 排除 |
換個角度看模型空間的事後分佈:
| 模型形式 | 出現頻率 |
|---|---|
| 空模型(什麼變數都不放) | 99.52% |
| 只放一個變數的模型(合計) | 0.48% |
| 放兩個或以上的模型 | 0.00% |
這個分佈非常極端。在 5,000 次後期 MCMC 樣本中, 有 4,976 次選擇空模型 ,剩下的 24 次散落在「單獨放一個變數」的空間裡,且每個變數都不超過 0.12% 的支持度。
樣本外預測:誰贏了?
光看 PIP 不夠,還要看實際樣本外預測表現。我們用 Patton (2011) 的 QLIKE 損失函數衡量(數字越接近零越差,越負越好):
| 模型 | QLIKE | 與 baseline 的差距 |
|---|---|---|
| GJR baseline(最大概似估計) | −8.2703 | — |
| GARCH-X(保留全部 6 個變數) | −8.3521 | 改善 0.99% |
| GARCH-X(按 SSVS 選擇 = 空模型) | −8.1591 | 惡化 1.34% |
| GARCH-X(單獨放最強的 VIX3M) | −8.1755 | 惡化 1.15% |
兩個比較檢定都達顯著水準(嚴格統計強度門檻通過):
- 基準 vs. 「保留全部變數版本」:兩模型比較顯著( 通過嚴格統計檢驗門檻 )
- 基準 vs. 「單獨放最強變數版本」:兩模型比較顯著( 通過嚴格統計檢驗門檻 ),但方向是 baseline 較佳
這裡有一個容易被誤讀的細節: 「保留全部變數」版本的 QLIKE 確實比 baseline 略好,但這不是因為外生變數有貢獻 。我們進去看後驗的 δ 估計值,所有六個變數的事後均值都在 1e-6 量級,乘上變數本身的數量級之後,對 h_t 的貢獻幾乎為零。那 0.99% 的微幅改善,主要來自於聯合估計過程中 α、β、γ 等基本 GARCH 參數本身被估到稍微不同的位置,而不是外生變數真的解釋了什麼。
換句話說: 統計上的差異是真的,但這個差異無法歸因給「VIX 等變數有預測力」 。
跟 K1013 的比較:兩種方法殊途同歸
K1031 最重要的價值,其實是它跟先前 K1013 的對照:
| 項目 | K1013(兩階段法) | K1031(聯合估計) |
|---|---|---|
| 方法 | 先 MLE 估 GARCH → 殘差做 SSVS | 變異數方程內直接 joint MCMC |
| 最大 PIP | 0.0012 | 0.0012 |
| 空模型頻率 | 99.56% | 99.52% |
兩個結果幾乎一模一樣。這排除了「兩階段法低估了聯合效應」這個合理的疑慮—— 用更嚴謹的聯合估計,還是得到同樣的空模型結論 。
那為什麼 K988 看起來相反?
熟悉本系列實驗的讀者可能會問:之前的 K988 不是發現 VIX² 在 GARCH-X 模型裡是顯著的(兩模型比較統計強度很高)嗎?怎麼到了 K1031 反而被 SSVS 排除?
兩個實驗的關鍵差別不在「VIX 有沒有用」,而在 模型的數學結構不同 :
- K988 用「乘法結構」 :h_t = base_garch · τ(VIX),VIX 調節的是整個變異數的水平
- K1031 用「加法結構」 :h_t = base_garch + Σ δ_j · X_{j,t-1},VIX 只是外加一個常數項
這兩種設定在直觀意義上完全不同。乘法結構允許 VIX 把整個變異數曲面整體放大或縮小;加法結構只是在原本的變異數上「再加一點點」。SSVS 的 spike-slab 先驗本來就偏好稀疏模型,當變數的邊際貢獻是「加一點點」這種弱訊號時,被排除是合理的。
所以正確的解讀是: SSVS 在加法框架下選空模型,不代表 VIX 對波動率沒幫助;而是說「把 VIX 當成一個加法項丟進變異數方程」這個特定設定,的確沒有貢獻 。
實驗誠實揭露:MCMC 混合品質的限制
這個實驗有幾個必須坦白說明的方法論限制:
- 某些參數的有效樣本數(ESS)很低 :ω 的 ESS 只有 7,β 只有 9。理想上 ESS 應該至少幾百以上才稱得上良好混合。
- δ 的接受率極低 (0.4%–0.9%):但這是 SSVS 的合理現象,當變數被 spike prior 壓在零附近時,提案值幾乎都會被拒絕,這恰好反映「模型認為這個變數該被排除」。
- 後驗持續性比 MLE 低 :MCMC 估出來的持續性 (α+γ/2+β) 約 0.70,而 MLE 是 0.96。這個差距主要來自 β 的混合不完全。
- 僅測試 SPY 一個資產 :跨市場驗證留待後續。
- 僅測加法 specification :乘法版本的 SSVS 是合理的下一步。
值得注意的是:雖然 ω 和 β 的混合不理想,但 SSVS 的核心輸出,納入指標 ξ_j——是 Gibbs step 而非 Metropolis-Hastings step,其 PIP 估計的可靠性不直接受 δ 接受率影響。當 δ 值極小(被 spike prior 壓制)時,ξ_j 的條件後驗幾乎一定支持「排除」。所以雖然參數估計的精確度有限,但「空模型」的結論是穩健的。
對研究與實務的意涵
- 「丟越多變數越好」是錯的 :總體變數本身的故事性常常掩蓋了它們在嚴謹模型空間裡的實際邊際貢獻。
- GJR-GARCH 的內部動態出乎意料地強 :α、γ、β 的非線性遞迴結構,似乎已經把可預測的變異數成分捕捉得差不多了。
- 方法的「結構假設」決定一切 :同一組變數,在乘法結構裡可能顯著、在加法結構裡可能沒貢獻;這不是矛盾,而是建模選擇的後果。
- 空模型也是有價值的結論 :它告訴後續研究者,與其在加法 GARCH-X 框架裡繼續加變數,不如改變結構假設(multiplicative、regime-switching、neural network 等)或改變預測標的(尾部風險、跳躍頻率而非整體變異數)。
後續研究方向
- 乘法 SSVS :在 h_t = base_garch · exp(Σ δ_j X_j) 這種乘法結構下重做選變數
- 延長 MCMC :跑 20,000–50,000 次迭代以改善 ω/β 的混合
- 區塊採樣 :對 (ω, α, γ, β) 做 block Metropolis-Hastings 改善聯合混合
- 跨市場驗證 :先前的 K461 在台股上發現 SSVS 會選出 SPY 的相關項(PIP=1.000),跨市場結構可能更豐富
資料來源
- 價格資料 :yfinance(SPY 日收盤價,2011-01-04 至 2026-04-09)
- 總體變數 :FRED 本地快取(VIX、VIX9D、VIX3M、DGS10、DGS2、STLFSI4)
- 實驗代碼與完整結果 :experiments/k1031/k1031.py、experiments/k1031/k1031_results.json
- 隨機種子 :seed=42(所有 MCMC 採樣固定)
參考文獻
- So, M. K. P., Chen, C. W. S., & Liu, F.-C. (2006). "Best subset selection of autoregressive models with exogenous variables and generalized autoregressive conditional heteroscedasticity errors." Journal of the Royal Statistical Society: Series C, 55(2), 201–224.
- George, E. I., & McCulloch, R. E. (1993). "Variable selection via Gibbs sampling." Journal of the American Statistical Association, 88(423), 881–889.
- Patton, A. J. (2011). "Volatility forecast comparison using imperfect volatility proxies." Journal of Econometrics, 160(1), 246–256.
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊